
Mines Informatique MP-PC-PSI 2018
| Thème de l'épreuve | Mesures de houle |
| Principaux outils utilisés | taille et lecture de fichiers, calculs de moyenne et d'intégrale, recherche dans une liste, tri, SQL, récursivité |
| Mots clefs | houle, traitement de données numériques, transformée de fourier discrète, base de données |
Corrigé
:👈 gratuite pour tous les corrigés si tu crées un compte
👈 l'accès aux indications de tous les corrigés ne coûte que 1 € ⬅ clique ici
👈 gratuite pour tous les corrigés si tu crées un compte
- - -
👈 gratuite pour ce corrigé si tu crées un compte
- - - - - - - - - - - - - - - -

Énoncé complet
(télécharger le PDF)







Rapport du jury
(télécharger le PDF)


Énoncé obtenu par reconnaissance optique des caractères
A2018 * INFO
.
CONCOURS .:IVIINES
COMMUN : PONTS
ECOLE DES PONTS PARISTECH,
ISAE-SUPAERO, ENSTA PARISTECH,
TELECOM PARISTECH, MINES PARISTECH,
MINES SAINT--ETIENNE, MINES NANCY,
IMT Atlantique, ENSAE PARISTECH.
Concours Centrale-Supélec (Cycle International),
Concours Mines-Télécom, Concours Commun TPE / EIVP.
CONCOURS 2018
EPREUVE D'INFORMATIQUE COMMUNE
Durée de l'épreuve : 1 heure 30 minutes
L'usage de la calculatrice et de tout dispositif électronique est interdit.
Cette épreuve est commune aux candidats des filières MP, PC et PSI
Les candidats sont priés de mentionner de façon apparente
sur la première page de la copie :
INFORMATIQUE COlWM UNE
L'énoncé de cette épreuve comporte 10 pages de texte.
Si, au cours de l'épreuve, un candidat repère ce qui lui semble être une erreur
d 'énoncé, il le signale sur sa copie et poursuit sa composition en expliquant
les
raisons des initiatives qu'il est amené à prendre.
MESURES DE HOULE
Le sujet comporte des questions de programmation. Le langage à utiliser est
Python.
On s'intéresse à des mesures de niveau de la surface libre de la mer effectuées
par une bouée (re--
présentée sur la Figure 1) 1. Cette bouée contient un ensemble de capteurs
incluant un accéléromètre
vertical qui fournit, après un traitement approprié, des mesures à étudier?
FIGURE 1 : bouée de mesure de houle
Les mesures réalisées à bord de la bouée sont envoyées par liaison radio a une
station a terre
où elles sont enregistrées, contrôlées et diffusées pour servir a des études
scientifiques. Pour plus de
sûreté, les mesures sont aussi enregistrées sur une carte mémoire interne a la
bouée.
Partie I. Stockage interne des données
Une campagne de mesures a été effectuée. Les caractéristiques de cette campagne
sont les
suivantes :
* durée de la campagne : 15 jours;
-- durée d'enregistrement : 20 min toutes les demi--heures;
* fréquence d'échantillonnage : 2 Hz.
Les relevés de la campagne de mesure sont écrits dans un fichier texte dont le
contenu est défini
comme suit.
Les informations relatives à la campagne sont rassemblées sur la première ligne
du fichier,
séparées par des points--virgules (" ;"). On y indique différentes informations
importantes comme le
numéro de la campagne, le nom du site, le type du capteur, la latitude et la
longitude de la bouée,
la date et l'heure de la séquence.
1. Cette étude utilise des résultats extraits de la base de données du Centre
d'Archivage National des Données
de Houle In Situ. Les acquisitions ont été effectuées par le Centre d'Etudes
Techniques Maritimes Et Fluviales.
2. L'ensemble des paramètres des états de mer présent dans la base CANDHIS est
calculé par les logiciels :
-- Houle5 (CETMEF) : analyse vague par vague (temporelle) ;
-- PADINES (EDF / LNHE) : analyse spectrale et directionneHe (fréquentielle).
Les lignes suivantes contiennent les mesures du déplacement vertical (m).
Chaque ligne com--
porte 8 caractères dont le caractère de fin de ligne. Par exemple, on trouvera
dans le fichier texte
les 3 lignes suivantes :
+0 .4256
+0 . 3174
--0 . 0825
El Q1 -- On suppose que chaque caractère est codé sur 8 bits. En ne tenant pas
compte de la
première ligne, déterminer le nombre d'octets correspondant a 20 minutes
d'enregistrement a la
fréquence d'échantillonnage de 2 Hz.
Ü Q2 * En déduire le nombre approximatif (un ordre de grandeur suffira)
d'octets contenus dans le
fichier correspondant a la campagne de mesures définie précédemment. Une carte
mémoire de 1 Go
est--elle suffisante ?
:| Q3 -- Si, dans un souci de réduction de la taille du fichier, on souhaitait
ôter un chiffre significatif
dans les mesures, quel gain relatif d'espace mémoire obtiendrait--on ?
:| Q4 -- Les données se trouvent dans le répertoire de travail sous forme d'un
fichier donnees .txt.
Proposer une suite d'instructions permettant de créer à partir de ce fichier
une liste de flottants
liste_niveaux contenant les valeurs du niveau de la mer. On prendra garde a ne
pas insérer dans
la liste la première ligne du fichier.
Deux analyses sont effectuées sur les mesures : l'une est appelée "vague par
vague", l'autre est
appelée "spectrale".
Partie II. Analyse "vague par vague"
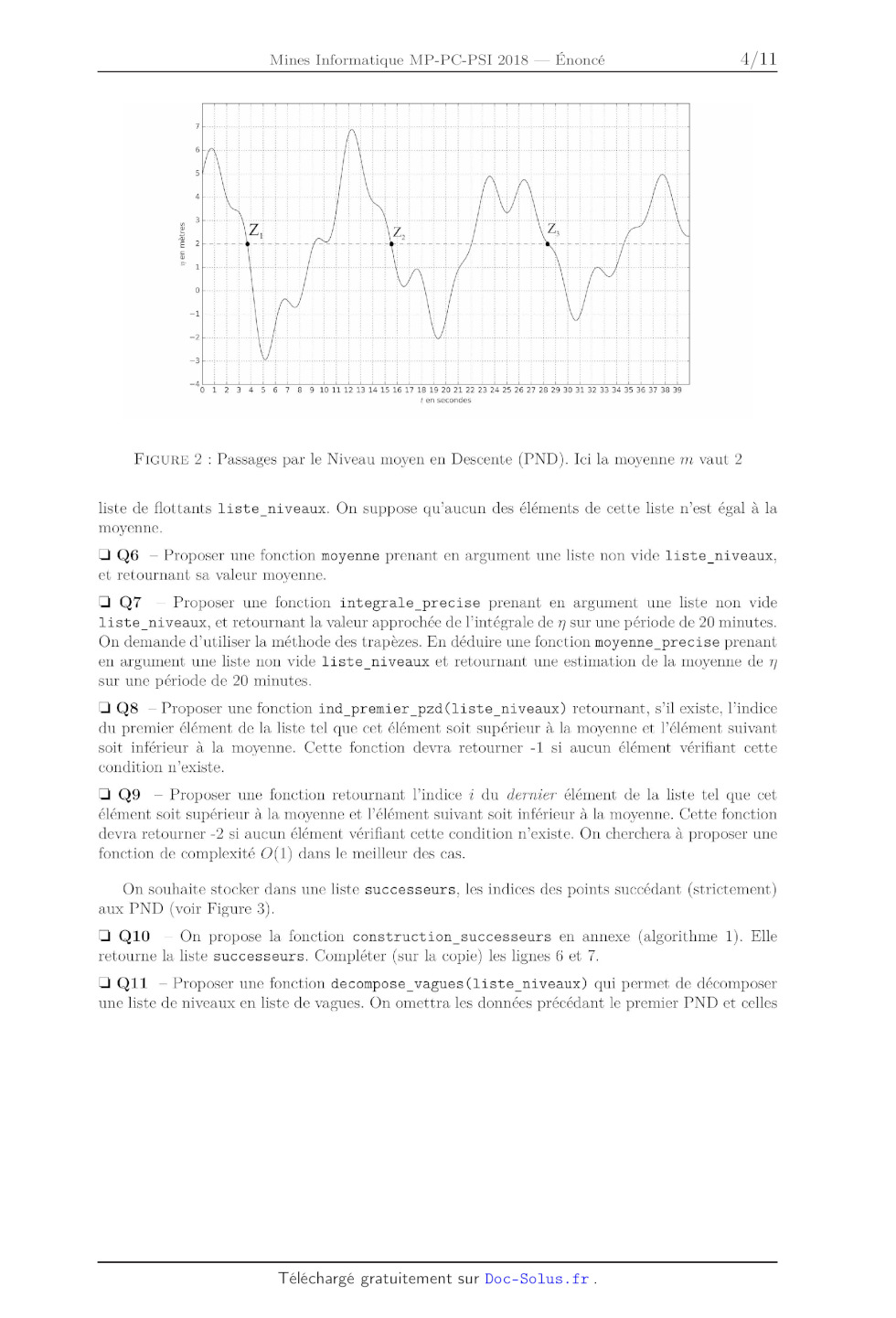
On considère ici que la mesure de houle est représentée par un signal 77(t) EUR
%, t E [O, T ], avec
77 une fonction Cl.
On appelle niveau moyen m la moyenne de 7705) sur [O, T].
On définit Zl, 22, ..., Z,, l'ensemble (supposé fini) des Passages par le
Niveau moyen en Descente
(PND) (voir Figure 2). A chaque PND, le signal traverse la valeur m en descente.
d
On suppose 77(0) > m, et d_'t7(0) > 0.
On en déduit que 77(t) -- m 2 0 sur [O, Zl].
Les hauteurs de vagues H,- sont définies par les différences :
H1 = max 77(t) -- min 77(t)
te[0, Z1] tEUR[Z1, Zæ]
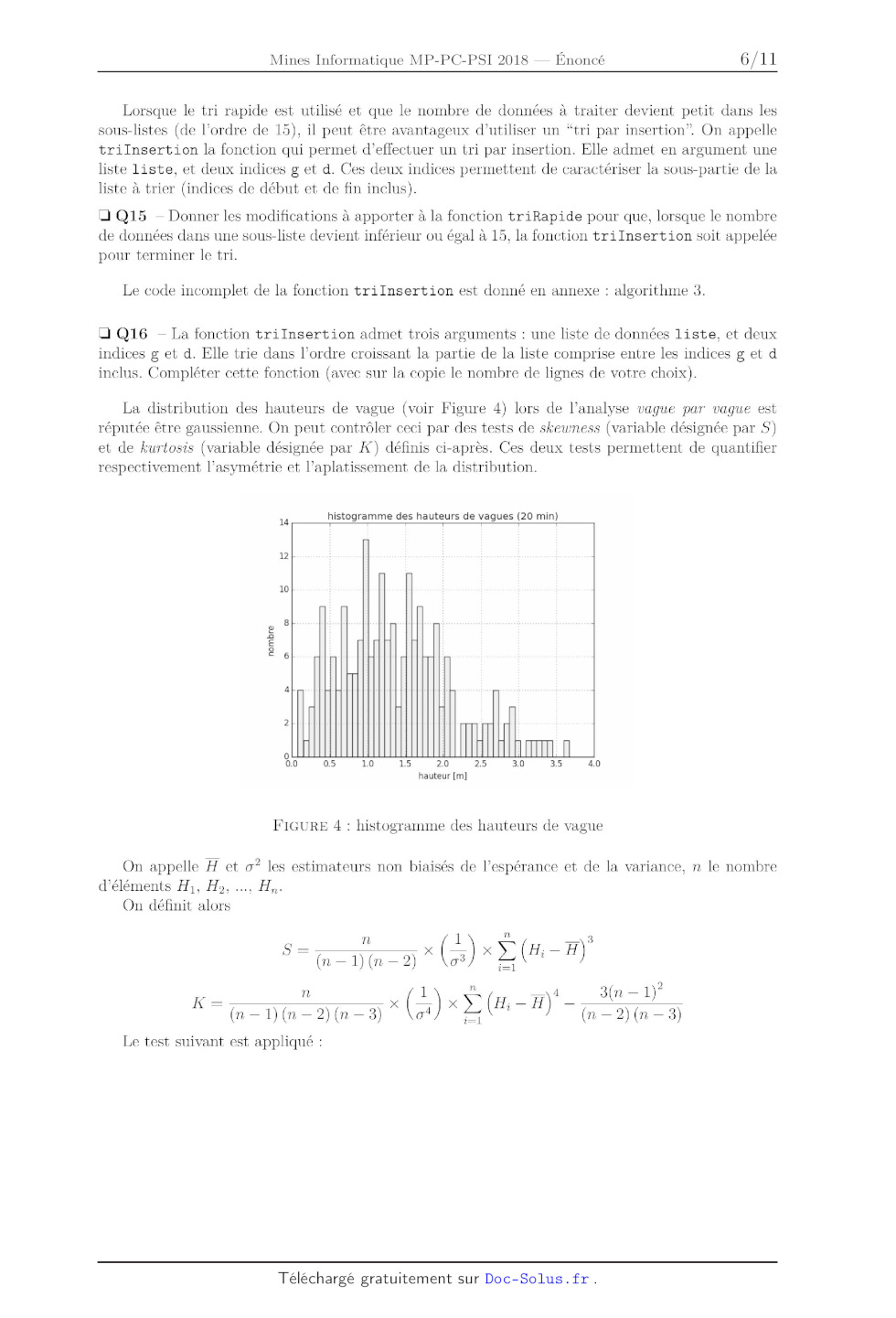
H, = max n(t) -- min n(t) pour2 5 z' < 71 tEUR[Zi,1, Z,] te[Z., Z...l On définit les périodes de vagues par T, = Z,-+1 -- Z,. Ü Q5 -- Pour le signal représenté sur la Figure 2, que valent approximativement H1, H2 et H3 ? Que valent approximativement T1 et T2 ? On adopte désormais une représentation en temps discret du signal. On appelle horodate, un ensemble (fini) des mesures réalisées sur une période de 20 minutes a une fréquence d'échantillon-- nage de 2 Hz. Les informations de niveau de surface libre d'un horodate sont stockées dans une 2 n en mètres N | I l I I I i l I l I l I l l I l I l I l I l I I l I l I l I l I l I l I l I l I l I l l I l I I I l I l I I I I I l l I I _3_ \ \ \ \ \ \ \ i \ i \ \ \ \ \ \ \ \ \ \ \ i \ \ \ . \ i \ '\ 0 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 t en secondes \;}\\\L11 01234567891 FIGURE 2 : Passages par le Niveau moyen en Descente (PND). Ici la moyenne m vaut 2 liste de flottants liste_niveaux. On suppose qu'aucun des éléments de cette liste n'est égal a la moyenne. :| Q6 * Proposer une fonction moyenne prenant en argument une liste non vide liste_niveaux, et retournant sa valeur moyenne. :| Q7 * Proposer une fonction integrale_precise prenant en argument une liste non vide liste_niveaux, et retournant la valeur approchée de l'intégrale de 77 sur une période de 20 minutes. On demande d'utiliser la méthode des trapèzes. En déduire une fonction moyenne_precise prenant en argument une liste non vide liste_niveaux et retournant une estimation de la moyenne de 77 sur une période de 20 minutes. Ü QS -- Proposer une fonction ind_premier_pzd(liste_niveaux) retournant, s'il existe, l'indice du premier élément de la liste tel que cet élément soit supérieur a la moyenne et l'élément suivant soit inférieur a la moyenne. Cette fonction devra retourner --1 si aucun élément vérifiant cette condition n'existe. Ü Q9 * Proposer une fonction retournant l'indice i du dernier élément de la liste tel que cet élément soit supérieur a la moyenne et l'élément suivant soit inférieur à la moyenne. Cette fonction devra retourner --2 si aucun élément vérifiant cette condition n'existe. On cherchera a proposer une fonction de complexité O(1) dans le meilleur des cas. On souhaite stocker dans une liste successeurs, les indices des points succédant (strictement) aux PND (voir Figure 3). :| Q10 -- On propose la fonction construction_successeurs en annexe (algorithme 1). Elle retourne la liste successeurs. Compléter (sur la copie) les lignes 6 et 7. :| Q11 -- Proposer une fonction decompose_vagues(liste_niveaux) qui permet de décomposer une liste de niveaux en liste de vagues. On omettra les données précédant le premier PND et celles Horodate échantillon niveau moyen _ indice point succédant au PND FIGURE 3 : propriétés d'une vague succédant au dernier PND. Ainsi decompose_vagues( [l, --1 , --2, 2, --2, --1 , 6, 4, --2, --5] ) (noter que cette liste est de moyenne nulle) retournera [[--1 , --2, 2] , [--2, --1 , 6, 4] ]. On désire maintenant caractériser les vagues. Ainsi, on cherche à concevoir une fonction proprietes (liste_niveaux) retournant une liste de listes à deux éléments [Hi ,Ti] permettant de caractériser chacune des vagues i par ses attributs : -- Hi, sa hauteur en mètres (m) (voir Figure 3), * Ti, sa période en secondes (S). D Q12 -- Proposer une fonction proprietes(liste_niveaux) réalisant cet objectif. On pourra utiliser les fonctions de Python max(L) et min(L) qui retournent le maximum et le minimum d'une liste L, respectivement. Partie III. Contrôle des données Plusieurs indicateurs sont couramment considérés pour définir l'état de la mer. Parmi eux, on note : Ü Q13 -- Proposer une fonction prenant en argument la liste liste_niveaux de la question 12 et retournant H...". Afin de déterminer H...; et TH1/3, il est nécessaire de trier la liste des propriétés des vagues. La méthode utilisée ici est un tri rapide (quick sort). On donne en annexe un algorithme possible pour la fonction triRapide (algorithme 2). Trois arguments sont nécessaires : une liste liste, et deux indices g et d. Ü Q14 * Préciser les valeurs que doivent prendre les arguments g et d au premier appel de la fonction triRapide. Compléter (sur la copie) la ligne 2. 4 Lorsque le tri rapide est utilisé et que le nombre de données a traiter devient petit dans les sous--listes (de l'ordre de 15), il peut être avantageux d'utiliser un "tri par insertion". On appelle trilnsertion la fonction qui permet d'effectuer un tri par insertion. Elle admet en argument une liste liste, et deux indices g et d. Ces deux indices permettent de caractériser la sous--partie de la liste à trier (indices de début et de fin inclus). Ü Q15 * Donner les modifications à apporter à la fonction triRapide pour que, lorsque le nombre de données dans une sous--liste devient inférieur ou égal a 15, la fonction tri Insert ion soit appelée pour terminer le tri. Le code incomplet de la fonction tri Insert ion est donné en annexe : algorithme 3. El Q16 * La fonction trilnsertion admet trois arguments : une liste de données liste, et deux indices g et d. Elle trie dans l'ordre croissant la partie de la liste comprise entre les indices g et (1 inclus. Compléter cette fonction (avec sur la copie le nombre de lignes de votre choix). La distribution des hauteurs de vague (voir Figure 4) lors de l'analyse vague par vague est réputée être gaussienne. On peut contrôler ceci par des tests de skewness (variable désignée par S) et de kur'tosis (variable désignée par K) définis ci--après. Ces deux tests permettent de quantifier respectivement l'asymétrie et l'aplatissement de la distribution. histogramme des hauteurs de vagues (20 min) 14 nombre 0 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 hauteur [m] FIGURE 4 : histogramme des hauteurs de vague On appelle Ë et 02 les estimateurs non biaisés de l'espérance et de la variance, n le nombre d'éléments H1, H2, ..., H... On définit alors --<>z<>
K: 71 x(1)xî(Hi--Ê)4_( 3(n--1)2
(n--1)(n--2)(n--3) i=1
Le test suivant est appliqué :
-- si la valeur absolue de S est supérieure a 0,3 alors l'horodate est déclaré
non valide;
-- si la valeur de K est supérieure a 5 alors l'horodate est déclaré non valide.
On utilise la fonction moyenne pour estimer la valeur de Ü, et on suppose
disposer de la fonction
ecartType qui permet de retourner la valeur de l'écart type non biaisé 0.
El Q17 * Un codage de la fonction skewness pour une liste ayant au moins 3
éléments est donné
en annexe (algorithme 4). Le temps d'exécution est anormalement long. Proposer
une modification
simple de la fonction pour diminuer le temps d'exécution (sans remettre en
cause le codage des
fonctions ecartType et moyenne).
Ü Q18 -- Doit--on s'attendre a une différence de type de la complexité entre
une fonction évaluant
S et une fonction évaluant K ?
Partie IV. Base de données relationnelle
On dispose d'une base de données relationnelle Vagues.
La première table est Bouee. On se limite aux attributs suivants : le numéro
d'identification
idBouee, le nom du site nomSite, le nom de la mer ou de l'océan localisation,
le type du capteur
typeCapteur et la fréquence d'échantillonnage frequence.
idBouee ' nomSite \ localisation \ typeCapteur ' frequence
Bouee 831 Porquerolles Mediterranee Datawell non directionnelle 2.00
291 Les pierres noires Mer d'iroise Datawell directionnelle 1.28
La seconde table est Campagne.
On se limite aux attributs suivants : le numéro d'identification idCampagne, le
numéro d'iden--
tification de la bouée idBouee, la date de début debutCampagne et la date de
fin finCampagne.
idCampagne \ idBouee ' debutCampagne \ finCampagne
Cam a ne 08301 831 01/01/2010 00h00 15/01/2010 00h00
p % 02911 291 15/10/2005 18h30 18/10/2005 08h00
La troisième table est Tempete. Les informations fournies relatives à un
événement "tempête"
sont les suivantes :
-- date de début et fin de tempête,
-- évolution des paramètres H...; et H...aoe en fonction du temps,
* le détail de certains paramètres non définis ici, obtenus au pic de tempête.
On se limite aux attributs suivants : le numéro d'identification de la tempête
idTempete,
le numéro d'identification de la bouée idBouee, la date de début debutTempete,
la date de fin
finTempete, la valeur maximale de hauteur de vague Hmax.
idTempete ' idBouee ' debutTempete ' finTempete \ Hmax
Tem ete 083010 831 07/01/2010 20h00 09/01/2010 15h30 5.3
p 029012 291 16/10/2005 08h30 18/10/2005 09h00 8.5
Le schéma de la base de données est donc : Vagues={Bouee, Campagne, Tempete}.
Ü Q19 -- Formuler les requêtes SQL permettant de répondre aux questions
suivantes :
-- "Quels sont le numéro d'identification et le nom de site des bouées
localisées en Méditerra--
née ?"
-- "Quel est le numéro d'identification des bouées où il n'y a pas eu de
tempêtes ?"
-- "Pour chaque site7 quelle est la hauteur maximale enregistrée lors d'une
tempête ?"
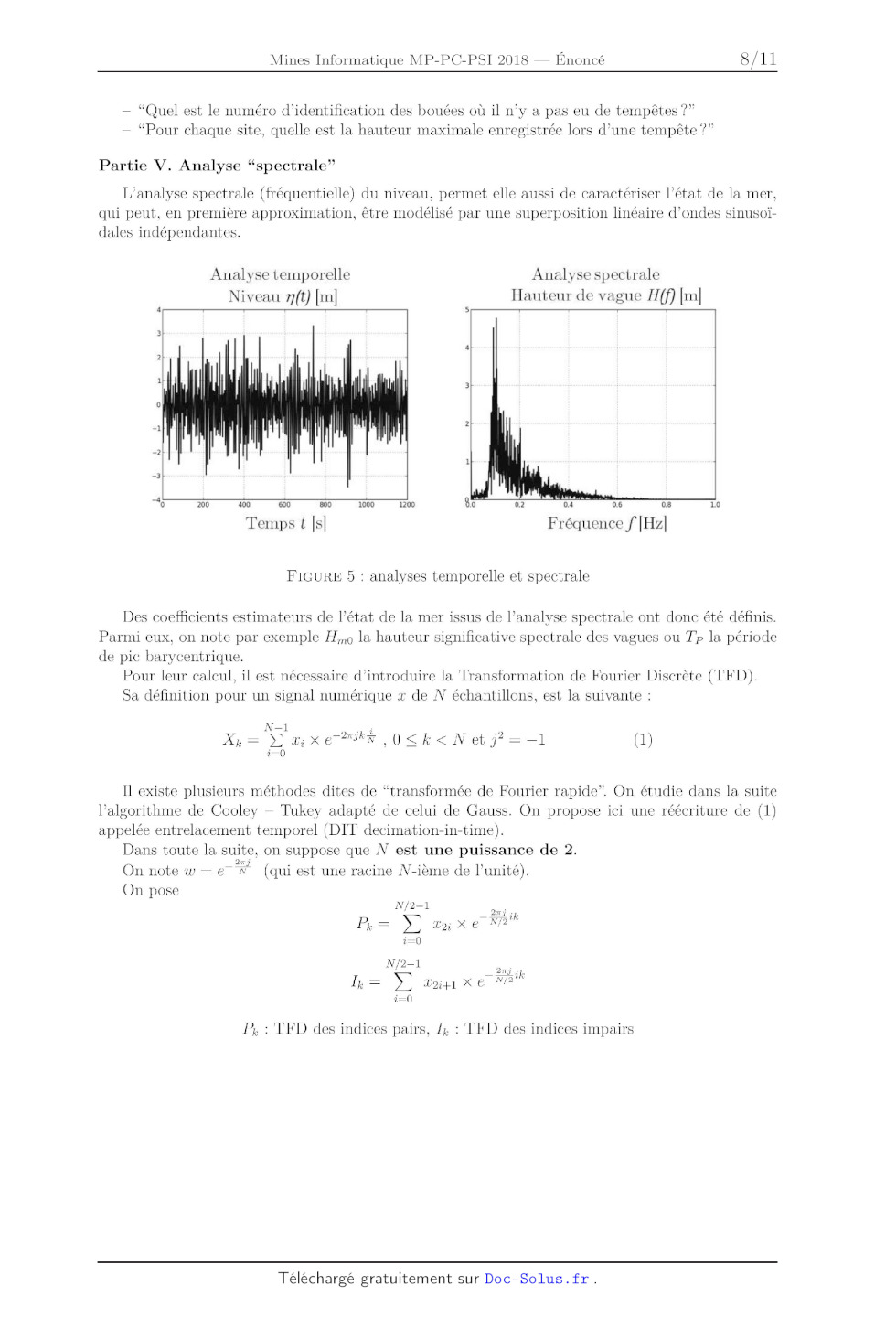
Partie V. Analyse "spectrale"
L'analyse spectrale (fréquentielle) du niveau, permet elle aussi de
caractériser l'état de la mer,
qui peut, en première approximation, être modélisé par une superposition
linéaire d'ondes sinusoï--
dales indépendantes.
Analyse te111porelle Analyse spectrale
Niveau 17(t) [111] Hauteur de vague HÛ') [111]
400 600 600 1000 1200 8.0 0.2 0 4 0 6 0 8 1.0
Temps t [s] Fréquencelez]
FIGURE 5 : analyses temporelle et spectrale
Des coefficients estimateurs de l'état de la mer issus de l'analyse spectrale
ont donc été définis.
Parmi eux, on note par exemple H...() la hauteur significative spectrale des
vagues ou T p la période
de pic barycentrique.
Pour leur calcul, il est nécessaire d'introduire la Transformation de Fourier
Discrète (TFD).
Sa définition pour un signal numérique a: de N échantillons, est la suivante :
N--1 _ ,
Xk=Ex,xe"2fiîkfi,Oîk< EUR_N_/2'k i=0 Pk : TFD des indices pairs, Ik : TFD des indices impairs Xk = Pk + zuka On montre alors ue our 0 < [EUR < Æ, q. p -- 2 Xk+N/2=Pk_wklk L'algorithme est de type "diviser pour régner" : le calcul d'une TFD pour N éléments se fait a l'aide de deux TFD de N / 2 éléments. :| Q20 -- Quelle est la complexité en temps de cet algorithme en fonction de N ? Justifier en une ou deux lignes. :| Q21 * Écrire une fonction récursz've prenant en argument la liste de données x et retournant la liste X obtenue par transformée de Fourier discrète rapide. La longueur de x est une puissance de 2. OO\ÏOEOEH>CJDM+--*
OO\ÏOEU'H>OÔNH
l--'i--'Hi--'HD--'Hl--'HH
©OO\ÏOEÜÎH>OÛMHOOED
OO\ÏOEÜÎH>CJDNH
l--'Hl--'l--'
OOl\Di--'O©
Annexe
Algorithme 1
def constructionÿsuccesseurs(listeÿniveaux):
n=len(liste_niveaux)
successeurs=[]
m=moyenne(listeÿniveaux)
for i in range(n--l)z
if #A completer
#A completer
return successeurs
Algorithme 2
def triRapide(liste ,g,d):
pivot= #A completer
i=g
j=d
while True:
while i<=d and liste [i][0]=g and liste[j][0]>pivotz
j=j--1
if i>j:
break
if iOÔM!--k
Algorithme 4
def skewness(listeÿhauteurs):
n=len(listeÿhauteurs)
et3=(ecartType(listeÿhauteurs))w«3
S=0
for i in range(n):
S--l--=(listeÿhauteurs [i]--moyenne( liste_hauteurs ))**3
S=n/(n--1)/(n--2)*S/et3
return 8
Fin de l'épreuve.
10