
CCINP Informatique PSI 2017
| Thème de l'épreuve | Étude de la capacité et de la congestion de l'autoroute A7 |
| Principaux outils utilisés | SQL, algorithmique, intégration numérique, automates cellulaires |
| Mots clefs | trafic routier, bouchons, schéma d'intégration |
Corrigé
:👈 gratuite pour tous les corrigés si tu crées un compte
👈 l'accès aux indications de tous les corrigés ne coûte que 1 € ⬅ clique ici
👈 gratuite pour tous les corrigés si tu crées un compte
- - - - - - - -
👈 gratuite pour ce corrigé si tu crées un compte
- - - - - - - - -

Énoncé complet
(télécharger le PDF)












Rapport du jury
(télécharger le PDF)

Énoncé obtenu par reconnaissance optique des caractères
SESSION 2017
PSIIN07
.
!
!
!
EPREUVE SPECIFIQUE - FILIERE PSI!
!!!!!!!!!!!!!!!!!!!!"
!
INFORMATIQUE
Vendredi 5 mai : 8 h - 11 h!
!!!!!!!!!!!!!!!!!!!!"
N.B. : le candidat attachera la plus grande importance à la clarté, à la
précision et à la concision de la
!"#$%&'()*+,'+-)+%$)#'#$&+./&+$0.)"+1+!.2"!.!+%.+3-'+2.-&+4-'+/.054.!+6&!.+-).+.!!.-!+#7")()%"8+'4+4.+
/'9)$4.!$+/-!+/$+%(2'.+.&+#.:!$+2(-!/-':!.+/$+%(02(/'&'()+.)+.;24'3-$)&+4./+!$'/()/+#./+')'&'$&':./+3-7'4+
a été amené à prendre.!
!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!"
!
!
!
!
Les calculatrices sont interdites
!
!
! Le sujet comporte 15 pages dont :
!
13 pages de texte de presentation et enonce du sujet ;
!
2 pages d'annexes.
!
!
Toute documentation autre que celle fournie est interdite.
!
!
!
!
REMARQUES PRELIMINAIRES
!
!
!
! L'epreuve doit etre traitee en langage Python. Les syntaxes sont rappelees en
annexe 2.
! Les differents algorithmes doivent etre rendus dans leur forme definitive sur
la copie a rendre (les
! brouillons ne seront pas acceptes).
!
Il est demande au candidat de bien vouloir rediger ses reponses en precisant
bien le numero de la
!
question traitee et, si possible, dans l'ordre des questions. La reponse ne
doit pas se cantonner a la
!
redaction de l'algorithme sans explication ; les programmes doivent etre
expliques et commentes.
!
!
!
!
1/15
!
Etude de la capacite et de la congestion de l'autoroute A7
I
Objectifs et demarche d'etude
Il existe plusieurs formes de congestions routieres, selon leur
cause : la congestion recurrente, la congestion previsible
(travaux, manifestations, meteo) et la congestion due aux
incidents et accidents, par definition imprevisibles. On
s'interesse ici au niveau de congestion recurrente qui peut
etre defini comme le surplus de demande qui amene la
congestion.
Cette etude se focalise sur la congestion routiere de l'autoroute A7 en France.
La section etudiee ne comporte ni entree
ni sortie. La longueur de l'axe est de 8,5 km et comporte 3
voies sauf au niveau de la derniere station (non etudiee ici).
Un seul sens de circulation est etudie.
La cartographie presentee sur la figure 1 donne l'implantation des differentes
stations de mesure, de la station M8A a
M8P, et des controles de sanction automatique (CSA). Ces
stations de mesure font partie du systeme de recueil automa- Figure 1
Cartographie de la zone
d'etude
tique des donnees (RAD) present sur les autoroutes.
Pour realiser les mesures, la chaussee est equipee de boucles
electromagnetiques connectees aux
stations qui remontent l'information vers un systeme central. Ces boucles
permettent de compter le
nombre de vehicules qui passent sur les routes et, dans le cadre de cette
etude, il s'agit de boucles
doubles qui permettent aussi d'estimer les vitesses.
La connaissance et le suivi du niveau de congestion recurrente permettent
ensuite d'envisager des
actions de regulation et d'amenagement de voirie. La simulation numerique est
alors employee pour
etudier differentes solutions d'amenagement ou proposer des solutions de
regulation dynamique du
trafic.
Objectifs
Le premier objectif est d'etablir le diagramme fondamental (trace du debit en
fonction de la concentration) caracteristique du troncon etudie a partir de
l'historique de donnees de comptage.
Le deuxieme objectif est de mettre en place une simulation numerique adaptee au
troncon etudie a
partir de deux modeles afin de tester deux approches numeriques differentes.
II
Traitement des donnees experimentales
La methodologie choisie ici pour estimer la capacite d'une route est celle
utilisee notamment par les
centres d'etudes techniques de l'equipement. Elle consiste a representer un
diagramme fondamental,
c'est-a-dire le debit q, nombre de vehicules par unite de temps, en fonction de
la concentration c,
nombre de vehicules par unite de longueur. Ce diagramme permet alors de
determiner les parametres
caracteristiques de la route.
2/15
II.1
Exploitation des donnees de mesure
II.1.1 Selection des mesures
L'ensemble des donnees produites par le reseau est archive dans une base de
donnees. Les variables d'interet moyennees par tranche de temps de 6 min pour
chaque point de mesure sont le
debit q exp, representatif du nombre de vehicules par unite de temps et la
vitesse moyenne v exp des
vehicules en ce point. On peut egalement acceder a la concentration, c exp, par
calcul etant donne que
c exp = q exp/v exp.
Une version simplifiee de cette base de donnees est reduite a deux tables.
La table STATIONS repertorie les stations de mesures ; elle
STATIONS
COMPTAGES
contient les attributs :
id station (cle primaire), entier identifiant chaque staid_comptage
id_station
id_station
nom
tion ;
date
nombre_voies
voie
nom, chaine de caracteres designant le nom de la staq_exp
tion ;
v_exp
nombre voies, entier donnant le nombre de voies de la
section d'autoroute.
La table COMPTAGES repertorie les differents enregistrements de donnees
realises au cours du
temps par les stations de comptage. Elle contient les attributs :
id comptage, entier identifiant chaque comptage ;
id station, entier identifiant la station concernee ;
date, entier datant la mesure ;
voie, entier numerotant la voie sur laquelle a ete effectuee la mesure ;
q exp, flottant donnant le debit mesure pendant 6 minutes ;
v exp, flottant donnant la vitesse moyenne mesuree pendant 6 minutes.
Q1. L'etude se focalise uniquement sur les mesures de l'une des stations, la
M8B. Ecrire une
requete SQL qui renvoie les donnees de comptage (id comptage, date, voie, q
exp, v exp)
mesurees a la station de comptage de nom M8B.
Le resultat de la requete precedente est stocke dans une nouvelle table
COMPTAGES M8B a cinq
colonnes (id comptage, date, voie, q exp, v exp).
On fait l'hypothese que les mesures sur les differentes voies d'une meme
station sont enregistrees
de facon synchronisee. Lors d'un enregistrement pour une station a trois voies,
on ecrit donc trois
lignes dans la table COMPTAGES avec trois dates identiques. Pour chacun des
enregistrements de
la station M8B, trois lignes avec trois dates identiques sont donc presentes
dans la nouvelle table
COMPTAGES M8B. Pour la suite de l'etude, les resultats experimentaux de chacune
des trois voies
doivent etre agreges pour se ramener a une voie unique.
Q2. Ecrire une requete SQL qui renvoie, pour chaque date des donnees de
COMPTAGES M8B,
le debit correspondant a la somme des debits de chaque voie.
De la meme facon, une requete SQL permet d'obtenir la moyenne des vitesses sur
l'ensemble des
trois voies pour chaque date des donnees de COMPTAGES M8B. Il n'est pas demande
d'ecrire
cette requete. Ainsi, dans la suite de l'etude, la portion d'autoroute sera
simplifiee en ne considerant
qu'une seule voie.
3/15
5-6)&*+,-.)$/0%*1*.4
On veut tracer le diagramme fondamental du troncon
d'autoroute etudie (figure 2). Suite au traitement de la
base de donnees, on dispose a present du tableau a une
dimension (aussi appele vecteur) des debits q exp (en
vehicules par heure) et du vecteur des vitesses v exp
(en kilometres par heure). Ces deux vecteurs possedent
nbmesures composantes avec nbmesures le nombre de points
de mesure a tracer. Pour chaque composante i, la relation
c exp[i] = q exp[i]/v exp[i] permet d'obtenir la concentration. L'utilisation
des tableaux a une dimension (ou vecteurs)
est rappelee en annexe 2.
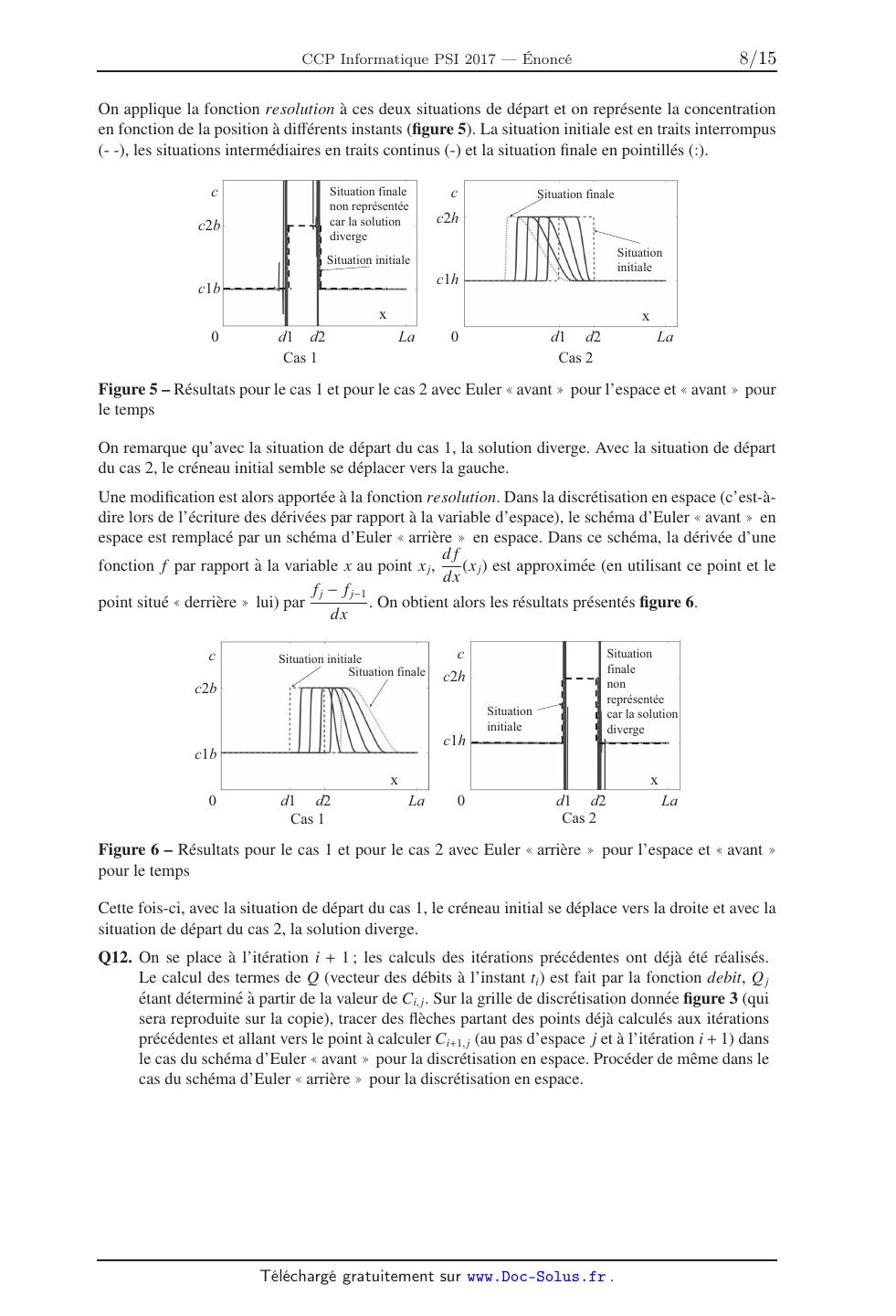
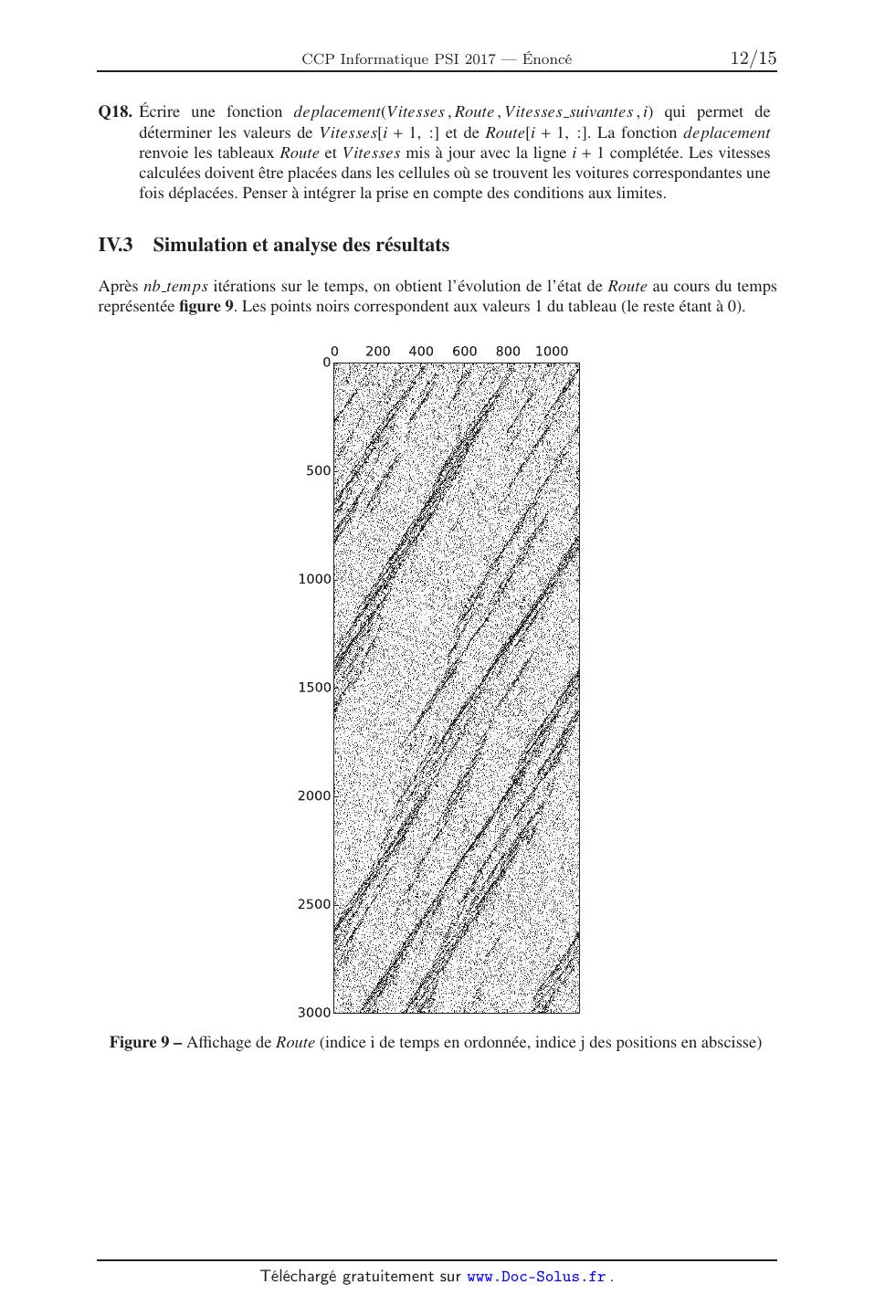
7***************:777*************;777*************<777**************=777* II.1.2 Diagramme fondamental 7 87 977 987 :77 !"#$%#&'(&)"#*+,-.)$/0%*1*234 Figure 2 Points de mesure M8B : diagramme fondamental (c exp,q exp) Q3. Ecrire une fonction trace(q exp , v exp) qui prend en arguments q exp et v exp et qui permet d'afficher le nuage de points du diagramme fondamental. On considerera que les bibliotheques sont importees et on pourra utiliser la fonction plot donnee en annexe 2. II.2 Estimation de l'etat de congestion Au niveau d'une station de mesure, la situation est dite congestionnee lorsque les vitesses prises par les vehicules restent inferieures a 40 km/h et la situation est dite fluide lorsque les vitesses restent superieures a 80 km/h. Q4. La fonction congestion(v exp), qui prend en argument v exp et renvoie la valeur mediane du tableau de valeurs v exp est definie ci-dessous. La recherche de la mediane est basee sur un algorithme de tri. Choisir une des 4 propositions donnees pour completer les 2 lignes manquantes (indiquees par ligne a completer ). Donner le nom, puis la complexite de l'algorithme de tri employe, dans le meilleur et le pire des cas. Analyser la pertinence de ce choix. def congestion(v_exp): nbmesures=len(v_exp) for i in range(nbmesures): v=v_exp[i] j = i while 0 < j and v < v_exp[j-1]: ligne a completer ligne a completer v_exp[j] = v return v_exp[nbmesures//2] Propositions pour les lignes manquantes : 1. v_exp[j-1] j = j-1 2. v_exp[j] = j = j-1 3. v_exp[j+1] j = j+1 4. v_exp[j] = j = j+1 = v_exp[j] v_exp[j-1] = v_exp[j] v_exp[j+1] Q5. A partir de la base de donnees de la station M8B, on obtient le vecteur v exp. On execute la fonction congestion(v exp), la valeur retournee par la fonction etant 30, quelle conclusion peut-on tirer de ce resultat? 4/15 III Elaboration d'une premiere simulation du trafic routier par la mecanique des fluides Il est rappele ici que dans toute la suite de l'etude, l'autoroute est assimilee a une seule voie. Le modele continu revient a negliger le caractere discret de la matiere. Pour le modele routier, cela revient donc a regarder l'evolution du trafic sur des distances grandes devant la taille des vehicules, notee L0. On appelle c(t,x), en vehicules par metre, la concentration de vehicules par unite de longueur de route a 1 l'instant t et a la position x. Sur une longeur L0, il y a, au plus, un seul vehicule, soit c c max = . L0 On appelle q(t,x), en vehicules par seconde, le debit de vehicules, c'est-a-dire le nombre de vehicules par unite de temps traversant la section de la route situee a la position x. La vitesse v(t,x), en metres par seconde, ne represente pas la vitesse de chacun des vehicules mais la vitesse moyenne du trafic a la position x. On considere que les vehicules se deplacent selon l'axe x dans le sens des x croissants. On rappelle la relation q(t,x) = c(t,x) × v(t,x). Desormais, q, v et c representent les grandeurs simulees et non plus des donnees experimentales. On travaille dans la suite avec les unites du systeme international. En considerant une portion d'autoroute dx pendant une duree dt et en supposant qu'il n'y a ni perte, ni creation de vehicule, il est possible de montrer que q(t,x) et c(t,x) verifient l'equation aux derivees partielles suivante : q(t,x) c(t,x) + = 0. (1) x t III.1 Discretisation Afin de resoudre numeriquement cette equation aux derivees partielles, nous avons besoin de la discretiser. On choisit les parametres suivants : longueur de l'autoroute : La duree de simulation : T emps pas d'espace (en metres) : dx pas de temps (en secondes) : dt Discrétisation en temps (indice i) Sens des temps croissants Pour comprendre comment evoluent la concentration, la vitesse moyenne ou le debit de vehicules au cours du temps le long de l'autoroute, il convient donc de resoudre cette equation aux derivees partielles a partir de la situation initiale. Discrétisation en espace (indice j) Sens des positions croissantes !"#$,%#$ !"#$,% !"#$,%&$ !",%#$ !",% !",%&$ !"&$,%#$ !"&$,% !"&$,%&$ Figure 3 Representation de la discretisation Q6. Soit C le tableau de valeurs contenant les concentrations en tous les points x et a tous les instants t discretises, comme represente sur la figure 3. L'approximation numerique de la concentration au temps ti et a la position x j sera notee Ci, j avec i designant l'indice de temps et j designant l'indice d'espace. Quelles sont les dimensions de C ? 5/15 III.2 Un modele de diagramme fondamental L'equation (1) possede deux inconnues. Il faut donc ajouter une deuxieme equation pour pouvoir la resoudre. On propose tout d'abord de relier la vitesse et la concentration par le modele de Greenshield etabli a partir des analyses suivantes : lorsque la concentration en vehicules tend vers 0, les conducteurs peuvent rouler a la vitesse maximale autorisee, v max en metres par seconde ; lorsque les vehicules sont pare-choc contre pare-choc, la concentration est egale a c max en vehicules par metre : ils n'avancent plus. Une relation lineaire entre vitesse et concentration est choisie dans le modele de Greenshield, qui est ainsi defini par la relation suivante : v(t,x) = v max(1 - c(t,x)/c max). (2) On souhaite concevoir une fonction diagramme permettant de realiser le trace du diagramme fondamental pour un instant donne ti (soit pour une ligne de C). Cette fonction fait appel a une fonction debit permettant de calculer les valeurs de debit a un instant ti en utilisant la relation de Greenshield (2). Ces valeurs sont stockees dans un vecteur Q. Le trace du diagramme fondamental est realise et le tableau Q est retourne. Q7. Ecrire une fonction debit(v max , c max , C ligne) qui prend en arguments la vitesse maximale (v max), la concentration maximale (c max) et un tableau contenant les concentrations a un instant donne (soit les elements d'une ligne du tableau C) nomme ici C ligne et qui renvoie un tableau de valeurs contenant les debits (en vehicules par seconde) aux differentes positions a ce meme instant. Q8. Specifier les arguments d'entree (et leur type) de la fonction diagramme. L'ecriture du code de la fonction n'est pas demandee. Preciser les unites des differents termes. Tracer l'allure du diagramme fondamental obtenu. L'allure du diagramme depend-elle du temps ti auquel on se place (soit du choix de la ligne de C)? Resolution de l'equation III.3.1 Situation initiale On considere une situation de depart (t = 0), comme indique sur la figure 4. On se place dans une configuration ou l'on a un profil de concentration dont on veut etudier l'evolution. La concentration c1 la plus faible passe a c2, plus forte, a la distance d1 et revient a c1 en d2. Chacune des distances sera discretisee. L'approximation numerique d'une distance correspondra a la division entiere de la distance par le pas. c2 Concentration III.3 c1 0 d1 d2 La !"#$%$"&'#()'*+,(%")"(%- Figure 4 Configuration initiale Q9. Concevoir une fonction C depart qui permet d'initialiser la premiere ligne du tableau C (correspondant a t = 0). L'ecriture du code correspondant n'est pas demandee ; en revanche, on precisera toutes les valeurs de j pour lesquelles C0, j sera egale a c1 et toutes les valeurs pour lesquelles C0, j sera egale a c2. L'en-tete ou specification de la fonction devra etre precise(e) (et comporter les arguments d'entree et leur type), ainsi que le resultat renvoye par la fonction. 6/15 III.3.2 Resolution Le tableau C contient des zeros, exceptee la premiere ligne qui a ete remplie de valeurs grace a la mise en oeuvre de la fonction C depart. On souhaite a present ecrire la fonction resolution(C , dt , dx , c max , v max) permettant de resoudre l'equation et de remplir completement le tableau C. Connaissant pour tout indice j les valeurs de Ci, j , on cherche a determiner Ci+1, j . Dans le schema d'Euler avant , la derivee d'une fonction f par rapport a la variable x, au point x j , f j+1 - f j df (x j ), est approximee (en utilisant ce point et le point situe devant lui) par . dx dx Q est un vecteur contenant les valeurs de debits Q j aux differentes positions x j et a l'instant ti (l'approximation du debit au temps ti et a la position x j sera donc notee Q j .). A chaque instant ti , Q devra etre recalcule. Q10. A partir de l'equation (1) et en utilisant des schemas d'Euler avant pour l'ecriture des derivees, montrer que la relation de recurrence donnant Ci+1, j en fonction de Ci, j , Q j+1 , Q j , dx et dt est donnee par l'une des propositions ci-dessous. Le numero de la reponse correcte sera clairement indique sur la copie. Q j - Q j+1 1. Ci+1, j = Ci, j - .dt dx Q j+1 - Q j .dt 2. Ci+1, j = Ci, j - dx Q j+1 - Q j .dx 3. Ci+1, j = Ci, j - dt Q j - Q j-1 .dt 4. Ci+1, j = Ci, j - dx Pour que le nombre de voitures soit constant sur la longueur de la route, il faut se fixer des conditions aux limites periodiques. Ainsi, quand un vehicule arrive en bout d'autoroute, il est replace au debut de celle-ci. On considere donc que le vehicule situe en x = La, se deplacant vers la droite, a pour voisin de droite le vehicule situe en x = 0. Q11. L'initialisation a ete effectuee avec la fonction C depart(dx , d1 , d2 , c1 , c2 , C). Ecrire une fonction resolution(C , dt , dx , c max , v max) qui prend en arguments le tableau C, les pas dt et dx, la concentration maximale c max et la valeur de la vitesse maximale v max et qui renvoie le tableau C rempli au cours de la resolution. On pourra faire appel a la fonction debit(v max , c max , C ligne) definie a la question Q7. III.4 Etude des solutions trouvees et modification du schema On etudie deux situations de depart basees sur le meme profil que celui propose a la situation initiale (figure 4). Dans le cas 1, on choisit c1 et c2, respectivement notees c1b et c2b, correspondant a des concentrations faibles. On peut montrer que, pour ces concentrations, le creneau se deplace vers la droite (dans le sens des x croissants) au cours du temps. Cette demonstration n'est pas demandee. Dans le cas 2, on choisit c1 et c2, respectivement notees c1h et c2h, correspondant a des concentrations fortes. On peut montrer que, pour ces concentrations, le creneau se deplace vers la gauche (dans le sens des x decroissants) au cours du temps. Cette demonstration n'est pas demandee. 7/15 On applique la fonction resolution a ces deux situations de depart et on represente la concentration en fonction de la position a differents instants (figure 5). La situation initiale est en traits interrompus (- -), les situations intermediaires en traits continus (-) et la situation finale en pointilles (:). ! %&'()'&*+,/&+)-. +*+,0.1023.+'2. 4)0,-),3*-('&*+, 5&6.07. !"% ! %&'()'&*+,/&+)-. !"& %&'()'&*+ &+&'&)-. %&'()'&*+,&+&'&)-. !$& !$% ! # ! "$ "" 8)3,$ #$ "$ "" 8)3," # #$ Figure 5 Resultats pour le cas 1 et pour le cas 2 avec Euler avant pour l'espace et avant pour le temps On remarque qu'avec la situation de depart du cas 1, la solution diverge. Avec la situation de depart du cas 2, le creneau initial semble se deplacer vers la gauche. Une modification est alors apportee a la fonction resolution. Dans la discretisation en espace (c'est-adire lors de l'ecriture des derivees par rapport a la variable d'espace), le schema d'Euler avant en espace est remplace par un schema d'Euler arriere en espace. Dans ce schema, la derivee d'une df fonction f par rapport a la variable x au point x j , (x j ) est approximee (en utilisant ce point et le dx f j - f j-1 point situe derriere lui) par . On obtient alors les resultats presentes figure 6. dx ! %&'()'&*+,&+&'&)-. %&'()'&*+,/&+)-. ! !"& %&'()'&*+, /&+)-. +*+, 0.1023.+'2. 4)0,-),3*-('&*+, 5&6.07. !"% %&'()'&*+ &+&'&)-. !$& !$% ! ! # "$ "" 8)3,$ #$ # "$ "" 8)3," #$ Figure 6 Resultats pour le cas 1 et pour le cas 2 avec Euler arriere pour l'espace et avant pour le temps Cette fois-ci, avec la situation de depart du cas 1, le creneau initial se deplace vers la droite et avec la situation de depart du cas 2, la solution diverge. Q12. On se place a l'iteration i + 1 ; les calculs des iterations precedentes ont deja ete realises. Le calcul des termes de Q (vecteur des debits a l'instant ti ) est fait par la fonction debit, Q j etant determine a partir de la valeur de Ci, j . Sur la grille de discretisation donnee figure 3 (qui sera reproduite sur la copie), tracer des fleches partant des points deja calcules aux iterations precedentes et allant vers le point a calculer Ci+1, j (au pas d'espace j et a l'iteration i + 1) dans le cas du schema d'Euler avant pour la discretisation en espace. Proceder de meme dans le cas du schema d'Euler arriere pour la discretisation en espace. 8/15 Q13. En deduire un argument permettant de choisir le schema d'Euler adapte a la situation de depart. On cherche maintenant un schema fonctionnel pour les deux situations. On propose celui de LaxFriedriechs qui : utilise un schema centre pour l'approximation des derivees par rapport a la variable d'espace. df Dans ce schema, la derivee d'une fonction f par rapport a la variable x au point x j , (x j ) est dx f j+1 - f j-1 approximee (a partir du point precedent et du point suivant) par ; 2dx approxime les derivees par rapport a la variable de temps en remplacant la valeur Ci, j par la moyenne de la valeur prise au point precedent Ci, j-1 et de la valeur prise au point suivant Ci, j+1 . Q14. Proposer les modifications de la fonction resolution (definie a la question Q11) necessaires pour utiliser le schema de Lax-Friedriechs. La mise en oeuvre de la fonction resolution permet, ensuite, d'effectuer le trace des solutions obtenues dont le resultat est donne figure 7. Les instructions permettant de realiser le trace ne sont pas demandees. Figure 7 Les deux situations de depart resolues avec le schema de Lax-Friedriechs III.5 Amelioration du programme : retour sur le choix du diagramme fondamental Afin de s'assurer de la stabilite de la solution trouvee, il convient, une fois le schema d'approximation determine, de definir les valeurs des parametres tels que les pas de temps et d'espace. On suppose ici que ce travail a ete realise. Cependant, cela ne signifie pas que l'on peut simuler fidelement des phenomenes reels. En effet, le diagramme fondamental utilise et trace a la question Q8 est assez different du nuage de points experimentaux represente figure 2. La nouvelle approximation choisie pour obtenir les parametres caracteristiques du diagramme fondamental q en fonction de c est une regression d'ordre 3 : q = a3 c3 + a2 c2 + a1 c + a0 , ai etant les constantes d'ajustement de la courbe sur le nuage de n points. La fonction regression(q exp , c exp), qui prend en arguments les vecteurs q exp et c exp obtenus experimentalement (ayant servi a tracer le nuage de points de la figure 2) et qui renvoie les coefficients a0 ,a1 ,a2 ,a3 , a ete realisee (on ne demande pas d'ecrire cette fonction). Q15. Expliquer en quelques phrases ce qu'il faut modifier dans la fonction resolution definie a la question Q11 pour resoudre l'equation (1) en prenant en compte ce nouveau diagramme fondamental base sur l'experimentation. La simulation que nous avons mise en place permet ainsi de determiner les caracteristiques d'evolution d'un embouteillage. On peut notamment en deduire la vitesse de propagation de l'embouteillage, ou sa vitesse de resorption. Cependant, on aimerait a present mettre en place une simulation permettant de modeliser les comportements individuels des conducteurs. 9/15 IV Deuxieme simulation du trafic routier : simulation de Nagel et Schreckenberg (NaSch) L'objectif est de simuler la formation d'embouteillages dits embouteillages fantomes . Ils sont le resultat d'une perturbation qui apparait localement sur la voie et s'amplifie peu a peu jusqu'a former un embouteillage. IV.1 Initialisation Afin de modeliser le comportement de chacun des vehicules, l'espace, le temps ainsi que la vitesse des vehicules sont discretises. La dynamique de chaque element est modelisee de facon tres simple, l'objectif etant d'obtenir un bon comportement a l'echelle macroscopique. On etudie, comme dans les parties precedentes, une autoroute de longueur La = 8 500 (en metres) pour laquelle on ne considere qu'un seul sens et qu'une seule voie. La vitesse est limitee a 130 km/h et on considere une duree totale d'etude T emps. Soit Xn la position du vehicule n, vn [[0,1,...,v max]] sa vitesse entiere et dn la distance intervehiculaire (par rapport au vehicule precedent). On choisit de decouper la route en nb cellules cellules de tailles identiques valant pas x = 7,5 (en metres). La duree d'etude est decoupee en nb temps pas de temps valant pas t = 1,2 (en secondes) qui peut s'interpreter comme le temps de reaction du conducteur. Une probabilite donnee par le flottant p est utilisee dans l'algorithme. Q16. Justifier le choix de la valeur du pas d'espace. En deduire ce que vaut la vitesse v max imposee de 130 km/h en cellules par pas de temps. On arrondira au nombre entier superieur. Comme precedemment, la portion d'autoroute consideree est sans entree ni sortie. Les conditions limites seront periodiques, c'est-a-dire qu'un vehicule sortant de l'autoroute se retrouve instantanement a l'entree de celle-ci (avec la meme vitesse). On considere que les donnees du probleme pas x, pas t, T emps, La, v max, p sont, a present, renseignees dans le programme. On cherche, pour une densite donnee, a determiner les vitesses a chaque position au cours du temps, ainsi que l'occupation ou non de chacune des cellules. On met en place une structure de stockage constituee : d'un tableau Route de dimension nb temps × nb cellules qui contient des nombres binaires. Si, au pas de temps 10, la cellule 23 est occupee par un vehicule, alors Route[10,23] = 1, sinon Route[10,23] = 0 ; d'un tableau Vitesses de dimension nb temps × nb cellules qui contient des entiers. Si, au pas de temps 10, la cellule 23 est occupee par un vehicule et que sa vitesse est de 3 cellules par pas de temps, alors Vitesses[10,23] = 3. Si la cellule n'est pas occupee, alors Vitesses[10,23] = 0 ; d'un tableau Vitesses suivantes de dimension 1 × nb cellules qui contient des entiers. Il permettra de stocker les vitesses au temps i + 1 avant de deplacer les vehicules. On peut desormais definir la situation initiale. On considere une route ou les ecarts entre tous les vehicules sont identiques. On cree ainsi une route avec une repartition homogene des vehicules. La route a ete initialisee en placant des 1 dans les cellules possedant un vehicule dans la premiere ligne de Route pour une concentration fixee c0 en vehicules par kilometre. Toutes les autres cellules de Route sont initialisees avec la valeur 0. Les cellules de Vitesses sont egalement initialisees avec des zeros. Cette etape d'initialisation est consideree comme deja realisee dans la suite. 10/15 IV.2 Mise en oeuvre de l'algorithme Le modele NaSch, dont le pseudo-code est donne en annexe 1, est le pionnier des modeles cellulaires permettant de simuler un trafic routier. L'algorithme est constitue de quatre etapes qui sont toutes realisees l'une apres l'autre a chaque pas de temps. Les etapes 1, 2 et 3 correspondent au calcul des futures vitesses. L'etape 4 permet d'inscrire chaque vitesse au lieu ou se trouve le vehicule au pas suivant. Le comportement correspondant est illustre figure 8. Dans cet algorithme, on effectue la mise a jour des positions de tous les vehicules de facon simultanee. Au niveau des etapes 2 et 4, des comparaisons et calculs sont effectues entre dn et vn ou entre Xn et vn . En effet, les vitesses sont exprimees en cellules par pas de temps. Sur un pas de temps, vn correspond donc a une distance parcourue en nombre de cellules. On cherche a ecrire la fonction ma j qui permet d'appliquer les etapes 1, 2 et 3 de l'algorithme de NaSch pour toutes les valeurs de Vitesses[i, :]. On utilisera la fonction distance(Route , i , j) qui prend en arguments le tableau Route, l'indice de temps i et l'indice de position j du vehicule n et qui renvoie la distance dn entre les vehicules n + 1 et n, a l'instant i. Seules les cellules comprenant un vehicule doivent etre traitees ; les autres auront une vitesse nulle. Sens de parcours Configuration à linstant t !"$ !"% !"% !"& !"$ !"$ !"% !"$ !"& !"% !"& !"% Etape 1 : Accélération !"# Etape 2 : Décélération !"% Mise à jour des vitesses Etape 3 : Facteur aléatoire !"& !"$ Etape 4 : Déplacement (Configuration à linstant t+1) !"& !"$ !"& !"% Figure 8 Illustration du schema sur un exemple Q17. En utilisant l'annexe 1, ecrire une fonction ma j(Route , Vitesses , p , vmax , i) qui prend en arguments les tableaux Route et Vitesses, le parametre aleatoire p, la vitesse maximale v max (en cellules par pas de temps) et l'indice de temps i et qui renvoie le tableau Vitesses suivantes. 11/15 Q18. Ecrire une fonction deplacement(Vitesses , Route , Vitesses suivantes , i) qui permet de determiner les valeurs de Vitesses[i + 1, :] et de Route[i + 1, :]. La fonction deplacement renvoie les tableaux Route et Vitesses mis a jour avec la ligne i + 1 completee. Les vitesses calculees doivent etre placees dans les cellules ou se trouvent les voitures correspondantes une fois deplacees. Penser a integrer la prise en compte des conditions aux limites. IV.3 Simulation et analyse des resultats Apres nb temps iterations sur le temps, on obtient l'evolution de l'etat de Route au cours du temps representee figure 9. Les points noirs correspondent aux valeurs 1 du tableau (le reste etant a 0). Figure 9 Affichage de Route (indice i de temps en ordonnee, indice j des positions en abscisse) 12/15 Un zoom est realise figure 10 sur les premieres valeurs en temps et en espace pour mieux visualiser la formation d'embouteillages. Figure 10 Zoom sur l'affichage de Route (indice i des temps en ordonnee, indice j des positions en abscisse) Q19. Expliquer en quelques phrases en quoi les figures presentees montrent que la formation d'un embouteillage a ete simulee. Sur quels parametres peut-on agir pour que le resultat de la simulation se rapproche des resultats experimentaux? 13/15 Annexes Annexe 1 - Algorithme de NaSch Les operations suivantes sont realisees a chaque pas de temps. Etape 1 - Acceleration Le vehicule n accelere d'une unite s'il n'a pas encore atteint la vitesse maximum. vn (t + 1) min (vn (t) + 1,v max) Etape 2 - Deceleration Le vehicule n decelere si la distance dn = Xn+1 - Xn par rapport au vehicule precedent ne permet pas de maintenir la vitesse vn . vn (t + 1) min (vn (t + 1),dn - 1) Etape 3 - Facteur aleatoire Pour caracteriser le comportement aleatoire de chacun des conducteurs, le vehicule n decelere avec une probabilite p, mais la vitesse n'est pas modifiee si vn (t+1) = 0 (pas de marche arriere). On utilise pour cela la fonction rand() qui renvoit une valeur aleatoire [0..1]. Si rand() < p alors vn (t + 1) max (vn (t + 1) - 1,0) Etape 4 - Deplacement Une fois les vitesses determinees, les positions des vehicules au pas de temps suivant sont determinees de facon simultanee. Xn (t + 1) Xn (t) + vn (t + 1) 14/15 Annexe 2 - Rappels des syntaxes en Python Remarque : sous Python, l'import du module numpy permet de realiser des operations pratiques sur les tableaux : from numpy import *. Les indices de ces tableaux commencent a 0. tableau a une dimension acceder a un element ajouter un element tableau a deux dimensions (matrice) acceder a un element extraire une portion de tableau (2 premieres colonnes) tableau de 0 ( 2 lignes, 3 colonnes) dimension d'un tableau T de taille (i, j) sequence equirepartie quelconque de 0 a 10.1 (exclus) par pas de 0.1 definir une chaine de caracteres Python L=[1,2,3] (liste) v=array([1,2,3]) (vecteur) v[0] renvoie 1 L.append(5) uniquement sur les listes M=array(([1,2,3],[3,4,5])) M[1,2] ou M[1][2] donne 5 M[:,0:2] zeros((2,3)) T.shape donne [i,j] arange(0,10.1,0.1) mot="Python" taille d'une chaine extraire des caracteres len(mot) mot[2:7] boucle For for i in range(10): print ( i ) condition If if (i>3):
print (i)
else:
print("hello")
definir une fonction qui possede un argument et
renvoie 2 resultats
def fonction(param):
res1=param
res2=param*param
return res1,res2
trace de points (o) de coordonnees (x,y)
plot(x,y,"o")
FIN
15/15