
Mines Informatique MP-PC-PSI 2016
| Thème de l'épreuve | Modélisation de la propagation d'une épidémie |
| Principaux outils utilisés | algorithmique, bases de données |
| Mots clefs | algorithme de tri, intégration numérique, automate cellulaire |
Corrigé
:👈 gratuite pour tous les corrigés si tu crées un compte
👈 l'accès aux indications de tous les corrigés ne coûte que 1 € ⬅ clique ici
👈 gratuite pour tous les corrigés si tu crées un compte
- - - - - - - - - - - - - - - - - - - -
👈 gratuite pour ce corrigé si tu crées un compte
- - -
Énoncé complet
(télécharger le PDF)







Rapport du jury
(télécharger le PDF)


Énoncé obtenu par reconnaissance optique des caractères
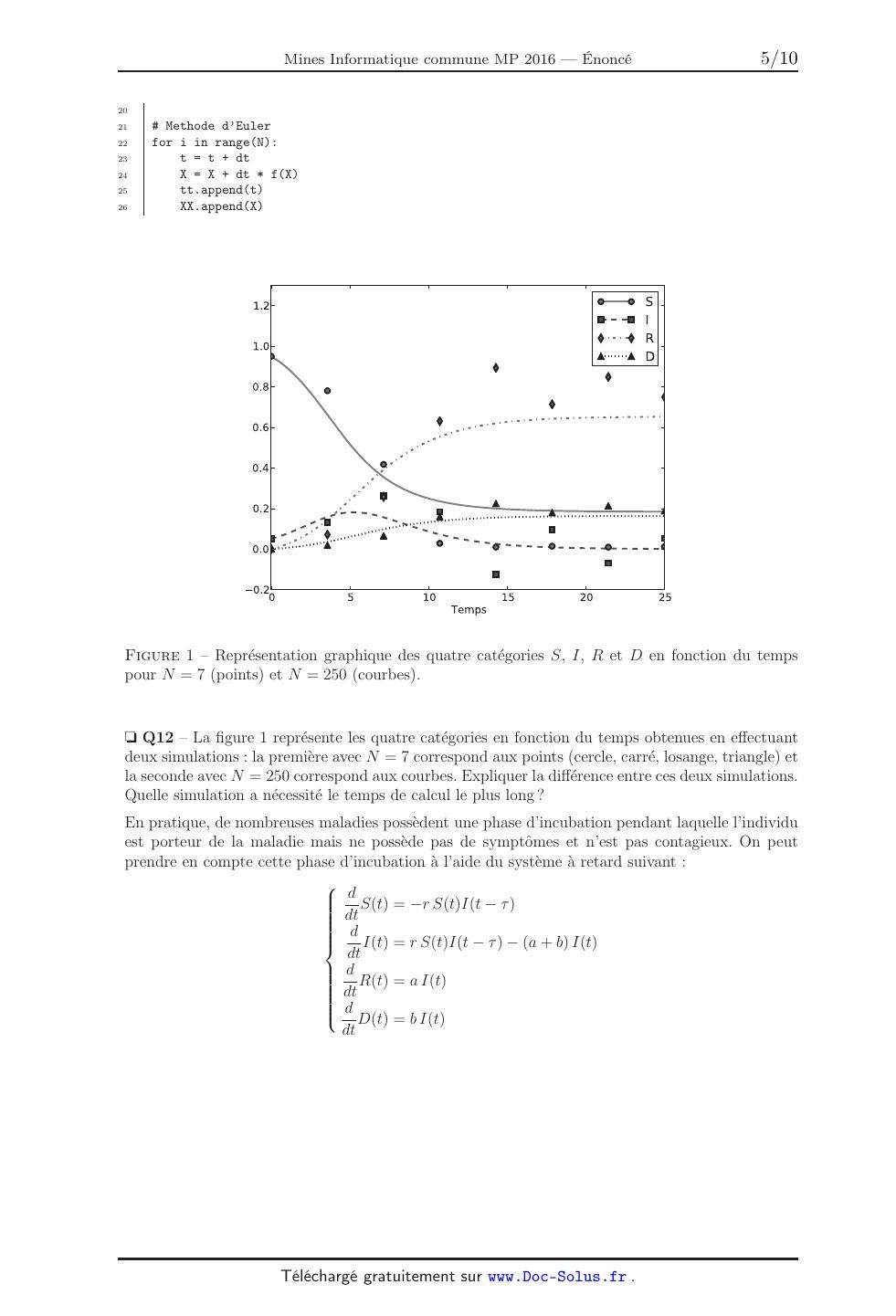
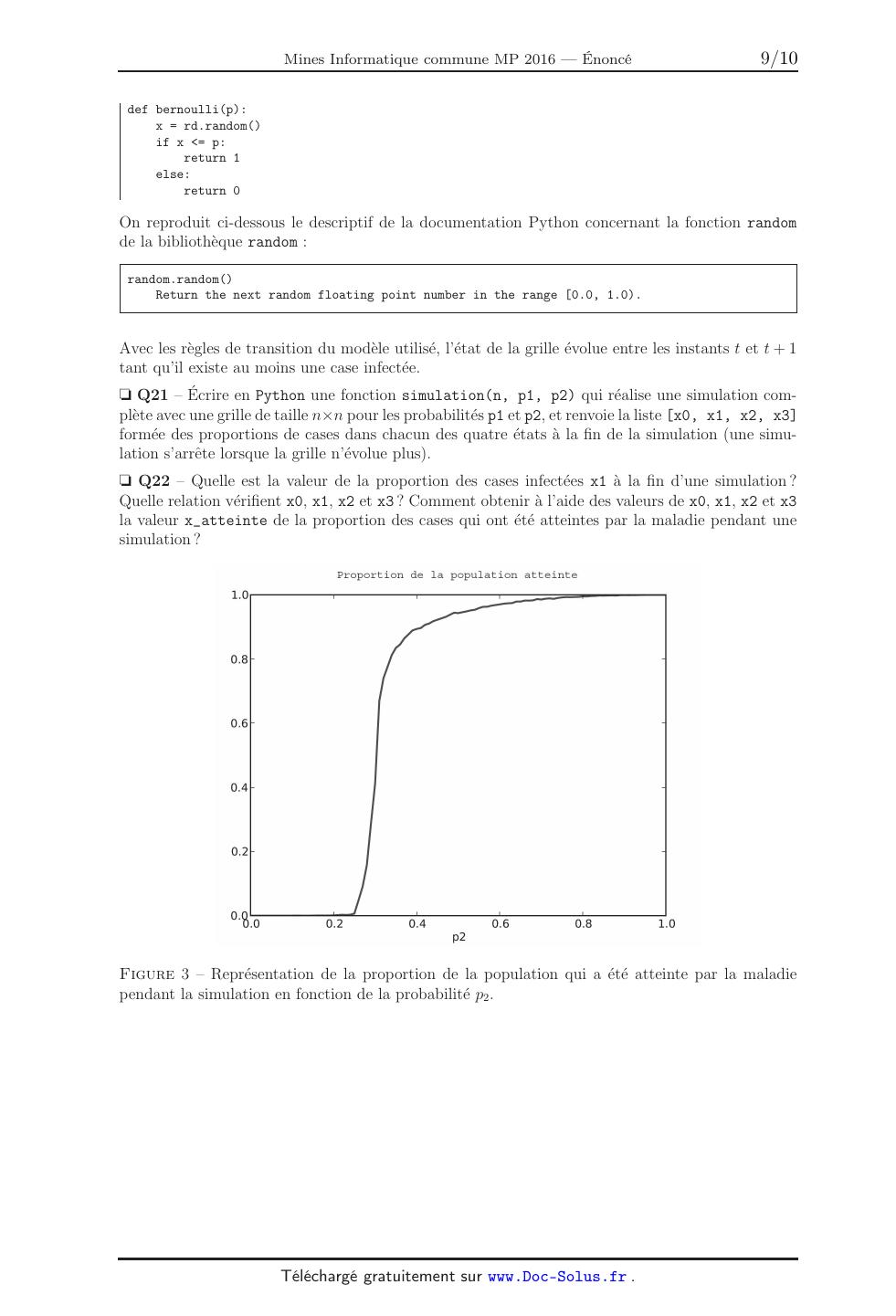
A 2016 - INFO. École des PONTS ParisTech, ISAE-SUPAERO, ENSTA ParisTech, TÉLÉCOM ParisTech, MINES ParisTech, MINES Saint-Étienne, MINES Nancy, TÉLÉCOM Bretagne, ENSAE ParisTech (Filière MP). CONCOURS 2016 ÉPREUVE D'INFORMATIQUE TOUTES LES FILIÈRES (Durée de l'épreuve : 1 h 30) L'usage de l'ordinateur ou de la calculatrice est interdit. Sujet mis à la disposition des concours : Concours Commun TPE/EIVP, Concours Mines-Télécom, Concours Centrale-Supélec (Cycle international). Les candidats sont priés de mentionner de façon apparente sur la première page de la copie : INFORMATIQUE L'énoncé de cette épreuve comporte 9 pages de texte. Si, au cours de l'épreuve, un candidat repère ce qui lui semble être une erreur d'énoncé, il le signale sur sa copie et poursuit sa composition en expliquant les raisons des initiatives qu'il est amené à prendre. Modelisation de la propagation d'une epidemie L'etude de la propagation des epidemies joue un role important dans les politiques de sante publique. Les modeles mathematiques ont permis de comprendre pourquoi il a ete possible d'eradiquer la variole a la fin des annees 1970 et pourquoi il est plus difficile d'eradiquer d'autres maladies comme la poliomyelite ou la rougeole. Ils ont egalement permis d'expliquer l'apparition d'epidemies de grippe tous les hivers. Aujourd'hui, des modeles de plus en plus complexes et puissants sont developpes pour predire la propagation d'epidemies a l'echelle planetaire telles que le SRAS, le virus H5N1 ou le virus Ebola. Ces predictions sont utilisees par les organisations internationales pour etablir des strategies de prevention et d'intervention. Le travail sur ces modeles mathematiques s'articule autour de trois themes principaux : traitement de bases de donnees, simulation numerique (par plusieurs types de methodes), identification des parametres intervenant dans les modeles a partir de donnees experimentales. Ces trois themes sont abordes dans le sujet. Les parties sont independantes. Dans tout le probleme, on peut utiliser une fonction traitee precedemment. On suppose que les bibliotheques numpy et random ont ete importees par : import numpy as np import random as rd Partie I. Tri et bases de donnees Dans le but ulterieur de realiser des etudes statistiques, on souhaite se doter d'une fonction tri. On se donne la fonction tri suivante, ecrite en Python : 1 2 3 4 5 6 7 8 9 def tri(L): n = len(L) for i in range(1, n): j = i x = L[i] while 0 < j and x < L[j-1]: L[j] = L[j-1] j = j-1 L[j] = x Q1 Lors de l'appel tri(L) lorsque L est la liste [5, 2, 3, 1, 4], donner le contenu de la liste L a la fin de chaque iteration de la boucle for. Q2 Soit L une liste non vide d'entiers ou de flottants. Montrer que « la liste L[0:i+1] (avec la convention Python) est triee par ordre croissant a l'issue de l'iteration i » est un invariant de boucle. En deduire que tri(L) trie la liste L. Q3 Evaluer la complexite dans le meilleur et dans le pire des cas de l'appel tri(L) en fonction du nombre n d'elements de L. Citer un algorithme de tri plus efficace dans le pire des cas. Quelle en est la complexite dans le meilleur et dans le pire des cas ? On souhaite, partant d'une liste constituee de couples (chaine, entier), trier la liste par ordre croissant de l'entier associe suivant le fonctionnement suivant : >>> L = [['Bresil', 76], ['Kenya', 26017], ['Ouganda', 8431]] >>> tri_chaine(L) >>> L [['Bresil', 76], ['Ouganda', 8431], ['Kenya', 26017]] 1 Q4 Ecrire en Python une fonction tri_chaine realisant cette operation. Pour suivre la propagation des epidemies, de nombreuses donnees sont recueillies par les institutions internationales comme l'O.M.S. Par exemple, pour le paludisme, on dispose de deux tables : la table palu recense le nombre de nouveaux cas confirmes et le nombre de deces lies au paludisme ; certaines lignes de cette table sont donnees en exemple (on precise que iso est un identifiant unique pour chaque pays) : nom iso annee cas deces Bresil BR 2009 309 316 85 Bresil BR 2010 334 667 76 Kenya KE 2010 898 531 26 017 Mali ML 2011 307 035 2 128 Ouganda UG 2010 1 581 160 8 431 ... la table demographie recense la population totale de chaque pays ; certaines lignes de cette table sont donnees en exemple : pays periode pop BR 2009 193 020 000 BR 2010 194 946 000 KE 2010 40 909 000 ML 2011 14 417 000 UG 2010 33 987 000 ... Q5 Au vu des donnees presentees dans la table palu, parmi les attributs nom, iso et annee, quels attributs peuvent servir de cle primaire ? Un couple d'attributs pourrait-il servir de cle primaire ? (on considere qu'une cle primaire peut posseder plusieurs attributs). Si oui, en preciser un. Q6 Ecrire une requete en langage SQL qui recupere depuis la table palu toutes les donnees de l'annee 2010 qui correspondent a des pays ou le nombre de deces dus au paludisme est superieur ou egal a 1 000. On appelle taux d'incidence d'une epidemie le rapport du nombre de nouveaux cas pendant une periode donnee sur la taille de la population-cible pendant la meme periode. Il s'exprime generalement en « nombre de nouveaux cas pour 100 000 personnes par annee ». Il s'agit d'un des criteres les plus importants pour evaluer la frequence et la vitesse d'apparition d'une epidemie. Q7 Ecrire une requete en langage SQL qui determine le taux d'incidence du paludisme en 2011 pour les differents pays de la table palu. Q8 Ecrire une requete en langage SQL permettant de determiner le nom du pays ayant eu le deuxieme plus grand nombre de nouveaux cas de paludisme en 2010 (on pourra supposer qu'il n'y a pas de pays ex æquo pour les nombres de cas). On considere la requete R qui s'ecrit dans le langage de l'algebre relationnelle : R = nom, deces (annee=2010 (palu)) On suppose que le resultat de cette requete a ete converti en une liste Python stockee dans la variable deces2010 et constituee de couples (chaine, entier). Q9 Quelle instruction peut-on ecrire en Python pour trier la liste deces2010 par ordre croissant du nombre de deces dus au paludisme en 2010 ? 2 Partie II. Modele a compartiments On s'interesse ici a une premiere methode de simulation numerique. Les modeles compartimentaux sont des modeles deterministes ou la population est divisee en plusieurs categories selon leurs caracteristiques et leur etat par rapport a la maladie. On considere dans cette partie un modele a quatre compartiments disjoints : sains (S, "susceptible"), infectes (I, "infected"), retablis (R, "recovered", ils sont immunises) et decedes (D, "dead"). Le changement d'etat des individus est gouverne par un systeme d'equations differentielles obtenues en supposant que le nombre d'individus nouvellement infectes (c'est-a-dire le nombre de ceux qui quittent le compartiment S) pendant un intervalle de temps donne est proportionnel au produit du nombre d'individus infectes avec le nombre d'individus sains. En notant S(t), I(t), R(t) et D(t) la fraction de la population appartenant a chacune des quatre categories a l'instant t, on obtient le systeme : d S(t) = -r S(t)I(t) dt d I(t) = r S(t)I(t) - (a + b) I(t) dt (1) d R(t) = a I(t) dt d D(t) = b I(t) dt avec r le taux de contagion, a le taux de guerison et b le taux de mortalite. On suppose qu'a l'instant initial t = 0, on a S(0) = 0,95 , I(0) = 0,05 et R(0) = D(0) = 0. Q10 Preciser un vecteur X et une fonction f (en donnant son domaine de definition et son expression) tels que le systeme differentiel (1) s'ecrive sous la forme d X = f (X). dt Q11 Completer la ligne 4 du code suivant (on precise que np.array permet de creer un tableau numpy a partir d'une liste donnant ainsi la possibilite d'utiliser les operateurs algebriques). 1 2 3 4 def f(X): """ Fonction definissant l'equation differentielle """ global r, a, b # a completer 5 6 7 8 9 10 11 # Parametres tmax = 25. r = 1. a = 0.4 b = 0.1 X0 = np.array([0.95, 0.05, 0., 0.]) 12 13 14 N = 250 dt = tmax/N 15 16 17 18 19 t = 0 X = X0 tt = [t] XX = [X] 3 20 21 22 23 24 25 26 # Methode d'Euler for i in range(N): t = t + dt X = X + dt * f(X) tt.append(t) XX.append(X) S I R D 1.2 1.0 0.8 0.6 0.4 0.2 0.0 0.2 0 5 10 Temps 15 20 25 Figure 1 Representation graphique des quatre categories S, I, R et D en fonction du temps pour N = 7 (points) et N = 250 (courbes). Q12 La figure 1 represente les quatre categories en fonction du temps obtenues en effectuant deux simulations : la premiere avec N = 7 correspond aux points (cercle, carre, losange, triangle) et la seconde avec N = 250 correspond aux courbes. Expliquer la difference entre ces deux simulations. Quelle simulation a necessite le temps de calcul le plus long ? En pratique, de nombreuses maladies possedent une phase d'incubation pendant laquelle l'individu est porteur de la maladie mais ne possede pas de symptomes et n'est pas contagieux. On peut prendre en compte cette phase d'incubation a l'aide du systeme a retard suivant : d S(t) = -r S(t)I(t - ) dt d I(t) = r S(t)I(t - ) - (a + b) I(t) dt d R(t) = a I(t) dt d D(t) = b I(t) dt 4 ou est le temps d'incubation. On suppose alors que pour tout t [-, 0], S(t) = 0,95 , I(t) = 0,05 et R(t) = D(t) = 0. En notant tmax la duree des mesures et N un entier donnant le nombre de pas, on definit le pas de temps dt = tmax/N . On suppose que = p × dt ou p est un entier ; ainsi p est le nombre de pas de retard. Pour resoudre numeriquement ce systeme d'equations differentielles a retard (avec tmax = 25, N = 250 et p = 50), on a ecrit le code suivant : 1 2 3 4 5 6 7 def f(X, Itau): """ Fonction definissant l'equation differentielle Itau est la valeur de I(t - p * dt) """ global r, a, b # a completer 8 9 10 11 12 13 # Parametres r = 1. a = 0.4 b = 0.1 X0 = np.array([0.95, 0.05, 0., 0.]) 14 15 16 17 18 tmax = 25. N = 250 dt = tmax/N p = 50 19 20 21 22 23 t = 0 X = X0 tt = [t] XX = [X] 24 25 26 27 28 29 30 # Methode d'Euler for i in range(N): t = t + dt # a completer tt.append(t) XX.append(X) Q13 Completer les lignes 7 et 28 du code precedent (utiliser autant de lignes que necessaire). On constate que le temps d'incubation de la maladie n'est pas necessairement le meme pour tous les individus. On peut modeliser cette diversite a l'aide d'une fonction positive d'integrale unitaire (dite de densite) h : [0, ] R+ telle que representee sur la figure 2. On obtient alors le systeme integro-differentiel : Z d I(t - s)h(s) ds S(t) = -r S(t) dt 0 Z d I(t) = r S(t) I(t - s)h(s) ds - (a + b) I(t) dt 0 d R(t) = a I(t) dt d D(t) = b I(t) dt 5 h(t) Fonction densite 0 t Figure 2 Exemple d'une fonction de densite. On supposera a nouveau que pour tout t [-, 0], S(t) = 0,95 , I(t) = 0,05 et R(t) = D(t) = 0. Pour j entier compris entre 0 et N , on pose tj = j × dt. Pour un pas de temps dt donne, on peut calculer numeriquement l'integrale a l'instant ti (0 i N ) a l'aide de la methode des rectangles a gauche en utilisant l'approximation : Z I(ti - s)h(s) ds dt × 0 p-1 X I(ti - tj )h(tj ). j=0 Q14 On suppose que la fonction h a ete ecrite en Python. Expliquer comment modifier le programme de la question precedente pour resoudre ce systeme integro-differentiel (on explicitera les lignes de code necessaires). Partie III. Modelisation dans des grilles On s'interesse ici a une seconde methode de simulation numerique (dite par automates cellulaires). Dans ce qui suit, on appelle grille de taille n × n une liste de n listes de longueur n, ou n est un entier strictement positif. Pour mieux prendre en compte la dependance spatiale de la contagion, il est possible de simuler la propagation d'une epidemie a l'aide d'une grille. Chaque case de la grille peut etre dans un des quatre etats suivants : saine, infectee, retablie, decedee. On choisit de representer ces quatre etats par les entiers : 0 (Sain), 1 (Infecte), 2 (Retabli) et 3 (Decede). L'etat des cases d'une grille evolue au cours du temps selon des regles simples. On considere un modele ou l'etat d'une case a l'instant t + 1 ne depend que de son etat a l'instant t et de l'etat de ses huit cases voisines a l'instant t (une case du bord n'a que cinq cases voisines et trois pour une case d'un coin). Les regles de transition sont les suivantes : une case decedee reste decedee ; une case infectee devient decedee avec une probabilite p1 ou retablie avec une probabilite (1 - p1 ) ; une case retablie reste retablie ; une case saine devient infectee avec une probabilite p2 si elle a au moins une case voisine infectee et reste saine sinon. On initialise toutes les cases dans l'etat sain, sauf une case choisie au hasard dans l'etat infecte. Q15 On a ecrit en Python la fonction grille(n) suivante 6 def grille(n) : M=[ ] for i in range(n) : L=[ ] for j in range(n): L.append(0) M.append(L) return M Decrire ce que retourne cette fonction. On pourra dans la question suivante utiliser la fonction randrange(p) de la bibliotheque random qui, pour un entier positif p, renvoie un entier choisi aleatoirement entre 0 et p - 1 inclus. Q16 Ecrire en Python une fonction init(n) qui construit une grille G de taille n × n ne contenant que des cases saines, choisit aleatoirement une des cases et la transforme en case infectee, et enfin renvoie G. Q17 Ecrire en Python une fonction compte(G) qui a pour argument une grille G et renvoie la liste [n0, n1, n2, n3] formee des nombres de cases dans chacun des quatre etats. D'apres les regles de transition, pour savoir si une case saine peut devenir infectee a l'instant suivant, il faut determiner si elle est exposee a la maladie, c'est-a-dire si elle possede au moins une case infectee dans son voisinage. Pour cela, on ecrit en Python la fonction est_exposee(G, i, j) suivante. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def est_exposee(G, i, j): n = len(G) if i == 0 and j == 0: return (G[0][1]-1)*(G[1][1]-1)*(G[1][0]-1) == 0 elif i == 0 and j == n-1: return (G[0][n-2]-1)*(G[1][n-2]-1)*(G[1][n-1]-1) == 0 elif i == n-1 and j == 0: return (G[n-1][1]-1)*(G[n-2][1]-1)*(G[n-2][0]-1) == 0 elif i == n-1 and j == n-1: return (G[n-1][n-2]-1)*(G[n-2][n-2]-1)*(G[n-2][n-1]-1) == 0 elif i == 0: # a completer elif i == n-1: return (G[n-1][j-1]-1)*(G[n-2][j-1]-1)*(G[n-2][j]-1)*(G[n-2][j+1]-1)*(G[n-1][j+1]-1) == 0 elif j == 0: return (G[i-1][0]-1)*(G[i-1][1]-1)*(G[i][1]-1)*(G[i+1][1]-1)*(G[i+1][0]-1) == 0 elif j == n-1: return (G[i-1][n-1]-1)*(G[i-1][n-2]-1)*(G[i][n-2]-1)*(G[i+1][n-2]-1)*(G[i+1][n-1]-1) == 0 else: # a completer Q18 Quel est le type du resultat renvoye par la fonction est_exposee ? Q19 Completer les lignes 12 et 20 de la fonction est_exposee. Q20 Ecrire une fonction suivant(G, p1, p2) qui fait evoluer toutes les cases de la grille G a l'aide des regles de transition et renvoie une nouvelle grille correspondant a l'instant suivant. Les arguments p1 et p2 sont les probabilites qui interviennent dans les regles de transition pour les cases infectees et les cases saines. On pourra utiliser la fonction bernoulli(p) suivante qui simule une variable aleatoire de Bernoulli de parametre p : bernoulli(p) vaut 1 avec la probabilite p et 0 avec la probabilite (1 - p). 7 def bernoulli(p): x = rd.random() if x <= p: return 1 else: return 0 On reproduit ci-dessous le descriptif de la documentation Python concernant la fonction random de la bibliotheque random : random.random() Return the next random floating point number in the range [0.0, 1.0). Avec les regles de transition du modele utilise, l'etat de la grille evolue entre les instants t et t + 1 tant qu'il existe au moins une case infectee. Q21 Ecrire en Python une fonction simulation(n, p1, p2) qui realise une simulation complete avec une grille de taille n×n pour les probabilites p1 et p2, et renvoie la liste [x0, x1, x2, x3] formee des proportions de cases dans chacun des quatre etats a la fin de la simulation (une simulation s'arrete lorsque la grille n'evolue plus). Q22 Quelle est la valeur de la proportion des cases infectees x1 a la fin d'une simulation ? Quelle relation verifient x0, x1, x2 et x3 ? Comment obtenir a l'aide des valeurs de x0, x1, x2 et x3 la valeur x_atteinte de la proportion des cases qui ont ete atteintes par la maladie pendant une simulation ? Figure 3 Representation de la proportion de la population qui a ete atteinte par la maladie pendant la simulation en fonction de la probabilite p2 . 8 On fixe p1 a 0,5 et on calcule la moyenne des resultats de plusieurs simulations pour differentes valeurs de p2. On obtient la courbe de la figure 3. Q23 On appelle seuil critique de pandemie la valeur de p2 a partir de laquelle plus de la moitie de la population a ete atteinte par la maladie a la fin de la simulation. On suppose que les valeurs de p2 et x_atteinte utilisees pour tracer la courbe de la figure 3 ont ete stockees dans deux listes de meme longueur Lp2 et Lxa. Ecrire en Python une fonction seuil(Lp2, Lxa) qui determine par dichotomie un encadrement [p2cmin, p2cmax] du seuil critique de pandemie avec la plus grande precision possible. On supposera que la liste Lp2 croit de 0 a 1 et que la liste Lxa des valeurs correspondantes est croissante. Pour etudier l'effet d'une campagne de vaccination, on immunise au hasard a l'instant initial une fraction q de la population. On a ecrit la fonction init_vac(n, q). 1 2 3 4 5 6 7 8 9 10 11 def init_vac(n, q): G = init(n) nvac = int(q * n**2) k = 0 while k < nvac: i = rd.randrange(n) j = rd.randrange(n) if G[i][j] == 0: G[i][j] = 2 k += 1 return G Q24 Peut-on supprimer le test en ligne 8 ? Q25 Que renvoie l'appel init_vac(5, 0.2) ? Fin de l'epreuve. 9