
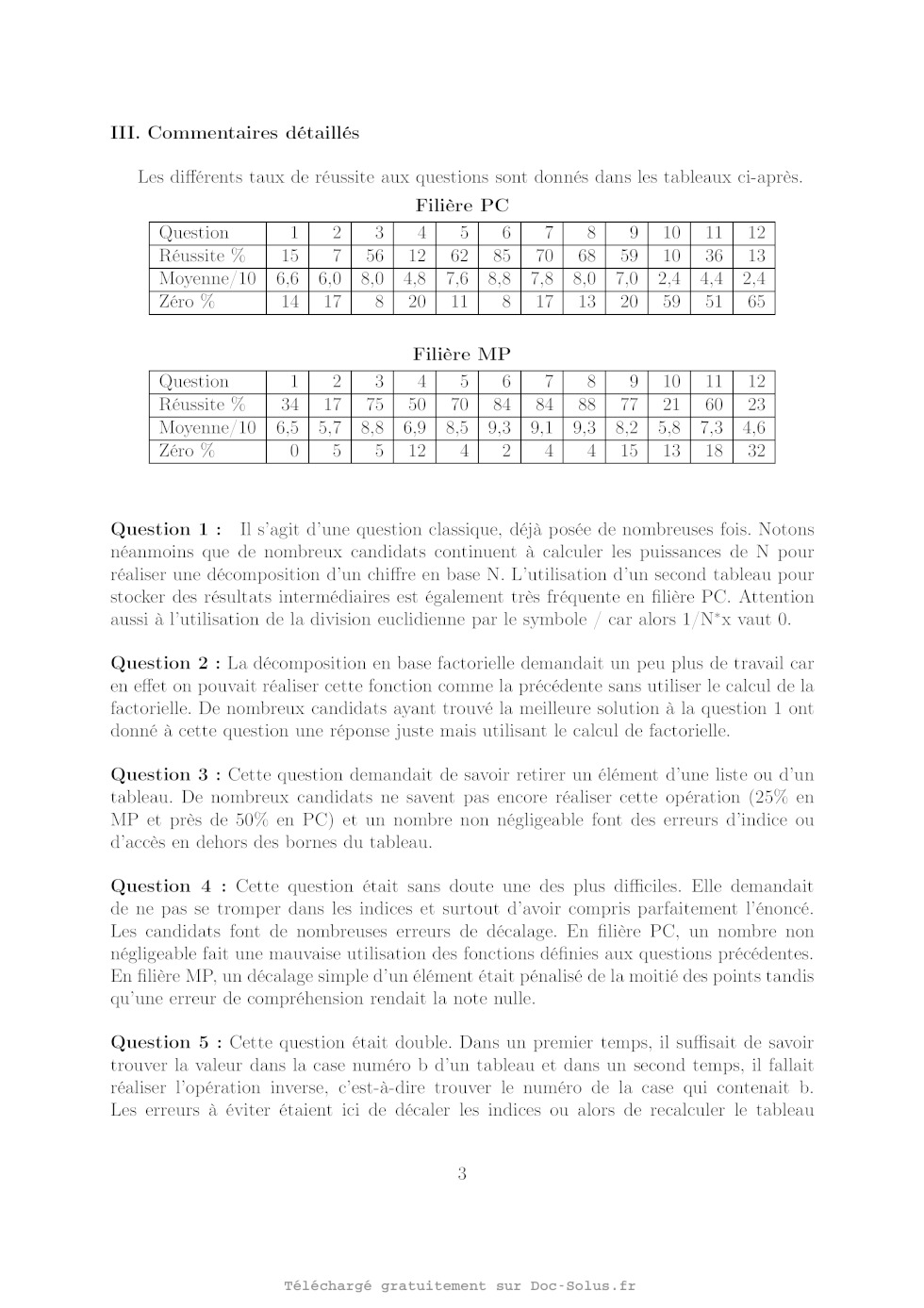
X Informatique MP/PC 2009
| Thème de l'épreuve | Chiffrement par blocs |
| Principaux outils utilisés | itération, programmation impérative |
| Mots clefs | Décomposition en base b, Réseau de Feistel |
Corrigé
: 👈 gratuite pour tous les corrigés si tu crées un compte👈 l'accès aux indications de tous les corrigés ne coûte que 5 € ⬅ clique ici
👈 gratuite pour tous les corrigés si tu crées un compte
- - - - - - - - - -
Énoncé complet
(télécharger le PDF)



Rapport du jury
(télécharger le PDF)


Énoncé obtenu par reconnaissance optique des caractères
ÉCOLE POLYTECHNIQUE
ÉCOLE SUPÉRIEURE DE PHYSIQUE ET CHIMIE INDUSTRIELLES
CONCOURS D'ADMISSION 2009
FILIÈRE
MP - OPTION PHYSIQUE ET SCIENCES DE L'INGÉNIEUR
FILIÈRE
PC
COMPOSITION D'INFORMATIQUE
(Durée : 2 heures)
L'utilisation des calculatrices n'est pas autorisée pour cette épreuve.
Le langage de programmation choisi par le candidat doit être spécifié en tête
de la copie.
Chiffrement par blocs
Notation. Dans tout l'énoncé, [[a, b [[ désigne l'ensemble des entiers naturels
supérieurs ou
égaux à a et strictement inférieurs à b.
Lorsque l'on souhaite communiquer des données confidentielles, il convient de
chiffrer ces
données, c'est-à-dire de les rendre inintelligibles. Les algorithmes étudiés
ici relèvent du chiffrement symétrique : une transformation de chiffrement
donnée est identifiée par une clé (un entier),
qui la désigne et permet également le déchiffrement.
Dans une approche simplifiée du chiffrement par blocs, le chiffrement d'un
message de taille
arbitraire est effectué d'abord en découpant le message en blocs de taille
fixée puis en chiffrant
chaque bloc. Nous nous limitons ici au chiffrement d'un bloc considéré
indépendamment des
autres. Dans ce modèle, on se donne un entier N > 0, dit taille (en pratique N
est une puissance
de deux). Un bloc (clair ou chiffré) est un entier de [[0, N [[, et un
algorithme de chiffrement est
une application de [[0, N [[ dans [[0, N [[. Pour permettre le déchiffrement,
cette application doit
être une permutation de [[0, N [[ (autrement dit une bijection).
Important. Dans tout le problème, on suppose que le langage de programmation
utilisé possède
certaines propriétés.
1. Les programmes agissent sur des entiers (naturels) « de taille arbitraire »
c'est-à-dire que
l'on ignore toutes les questions liées à la taille finie des entiers machine.
Autrement dit, on
considère que les opérations usuelles (+, etc.) sont celles des entiers
naturels.
2. Il existe deux fonctions rem(a, b) et quo(a, b) calculant respectivement le
reste r et le quotient q de la division euclidienne de a par b > 0. Il est
rappelé que l'égalité a = bq + r
et la condition r < b définissent q et r. Autrement dit, si a = bq + r, alors il existe un unique quotient q et un unique reste r < b, dont les valeurs sont données précisément par les fonctions quo et rem. 1 3. Certaines des fonctions demandées sont spécifiées comme renvoyant un tableau ou une liste. Tableau ou liste sont au choix du candidat. En cas de doute, le candidat est invité à définir les primitives dont il juge avoir besoin et à les employer de façon cohérente dans tout le problème. I. Approche naïve On cherche à désigner (dans un premier temps) une application arbitraire de [[0, N [[ (ensemble à N éléments) dans lui-même. Le nombre total de telles applications est N N . Considérons un entier k (une clé) pris dans [[0, N N [[. L'entier k s'écrit de manière unique sous la forme : k = aN -1 N N -1 + · · · + ai N i + · · · + a1 N 1 + a0 , où chaque coefficient vérifie ai [[0, N [[ (c'est l'écriture de k en base N ). On considère que k représente l'application fk de [[0, N [[ dans lui-même définie par fk (0) = a0 , fk (1) = a1 , etc. Question 1 Écrire la fonction DecomposerBase(N, k) qui prend en arguments la taille N , une clé k de [[0, N N [[, et qui renvoie la décomposition de k en base N . En pratique, DecomposerBase renvoie donc le tableau ou la liste des ai , dans l'ordre des i croissants. En réalité nous nous intéressons aux permutations de [[0, N [[. On sait qu'il existe N ! permutations d'un ensemble de N éléments. Dans la suite logique de la question précédente, considérons donc une clé k prise dans [[0, N ! [[. On admet que k s'écrit de manière unique sous la forme : k = aN -1 (N - 1)! + aN -2 (N - 2)! + · · · + ai i! + · · · + a2 2! + a1 1! + a0 , où les coefficients vérifient ai [[0, i + 1 [[. L'écriture ci-dessus est dite décomposition sur la base factorielle. Par exemple, pour N = 4 et k = 17, on a k = 2 · 3! + 2 · 2! + 1 · 1! + 0. Question 2 Écrire la fonction DecomposerFact(N, k) qui prend en argument la taille N et une clé k de [[0, N ! [[, et qui renvoie la décomposition de k sur la base factorielle. Une fois k décomposée sur la base factorielle, la permutation k de [[0, N [[ représentée par k se calcule comme suit. En premier lieu, on considère la séquence L = (0, 1, . . . , N - 1) à N éléments. Cette séquence est modifiée au fur et à mesure que les valeurs prises par la permutation k sont calculées. La première valeur calculée est k (0), égal au 1 + aN -1 -ième élément de L (c'est-à-dire à aN -1 ). Une fois k (0) calculé, cet entier est retiré de L, qui ne contient plus que N - 1 entiers. La seconde valeur calculée est k (1), égal au 1 + aN -2 -ième élément de L. Une fois k (1) calculé, cet entier est retiré de L. Le procédé est répété jusqu'au calcul de k (N - 1), égal à l'unique élément de L restant. Par exemple, dans le cas N = 4, k = 17 on a : 17 (0) = 2 (a3 = 2), et L devient (0, 1, 3). Ensuite 17 (1) = 3 (a2 = 2), et L devient (0, 1). Ensuite 17 (2) = 1 (a1 = 1), et pour finir 17 (3) = 0. 2 Question 3 Écrire la fonction Retirer(L, , j) qui prend en argument un tableau L à éléments, et qui renvoie un tableau de taille - 1. Le tableau renvoyé est une copie du tableau L dans laquelle le j-ème élément a été retiré. Question 4 Écrire la fonction EcrirePermutation(N, k) qui prend en arguments la taille N , la clé k de [[0, N ! [[, et qui renvoie la permutation k . La permutation sera représentée par le tableau ou la liste des k (i), dans l'ordre des i croissants. Question 5 Écrire les fonctions Chiffrer(N, k, b) et Dechiffrer(N, k, b), qui prennent en arguments la taille N , la clé k et un bloc b . La fonction Chiffrer renvoie k (b), tandis que la fonction Dechiffrer renvoie l'unique bloc b tel que k (b ) = b. II. Réseau de Feistel Nous prenons ici le parti de fabriquer des permutations particulières. Notre motivation ici est double : (1) réduire la taille des clés (un entier de [[0, N ! [[ dans la partie précédente) et (2) effectuer des calculs peu coûteux lors du chiffrement et du déchiffrement. On commence par fixer la taille à la valeur N = 264 . Un bloc b est donc un entier de [[0, 264 [[. L'ingrédient essentiel du chiffrement est le réseau de Feistel. Un réseau de Feistel est une suite de plusieurs opérations, appelées tours. Un tour est décrit par la figure 1. Sur la figure, l'entrée est le bloc bi = 232 qi +ri , la sortie est bi+1 = 232 qi+1 + ri+1 . qi ri Fki qi+1 ri+1 Fig. 1: Un tour de réseau de Feistel La figure peut aussi se lire comme définisssant qi+1 égal à ri , et ri+1 égal à qi Fki (ri ). Le symbole désigne ici une opération appelée xor. Cette fonction est associative, commutative, et vérifie xor(xor(x, y), y) = x pour tout couple d'entiers (x, y). On suppose que la fonction xor est disponible dans le langage de programmation utilisé, accessible sous le nom xor. Le symbole Fki désigne une application sur [[0, 232 [[, paramétrée par une clé ki . Par la suite, on suppose donnée une fonction F(ki , r) qui calcule Fki (r). Question 6 Écrire la fonction FeistelTour(k, b) qui prend en argument une clé k et un bloc b (k est un certain ki , et b est un certain bi ), et renvoie la sortie (notée bi+1 ci-dessus) du tour qui utilise la clé k. Question 7 Écrire la fonction FeistelInverseTour(k, b) qui réalise l'application inverse de la fonction précédente, c'est-à-dire qui calcule et renvoie bi en fonction de bi+1 . Question 8 Écrire la fonction Feistel(K, , b) qui prend en entrée le bloc b, et renvoie la sortie d'un réseau de Feistel à tours. Plus précisément, l'entrée b0 du premier tour est b, puis l'entrée bi (i > 0) d'un tour est la sortie du tour précédent. Enfin, la sortie
du réseau est la sortie
b du dernier tour. Chaque tour utilise une clé différente. Les clés sont
fournies (dans l'ordre) par
le tableau K de taille . Indépendamment du langage de programmation considéré,
on supposera
qu'un tableau est un argument standard et que ses indices sont les entiers de
[[0, [[.
Question 9 Écrire la fonction FeistelInverse(K, , b) qui effectue l'opération
inverse de la fonction
précédente. Cette opération inverse est le déchiffrement, et l'identité
suivante doit être vérifiée
pour tout bloc b :
FeistelInverse(K, , Feistel(K, , b)) = b.
3
III. Vérification de propriétés statistiques
Dans cette partie la taille N est fixée à la valeur N = 264 , comme dans la
partie précédente.
On explore la mise en oeuvre de critères de qualité du chiffrement. Certains
tests couramment
employés sont des tests statistiques effectués sur les message chiffrés. Ces
tests servent à mettre
en évidence des biais indésirables.
On considère le message clair (infini) formé de la séquence des blocs 0, 1, . .
. . Pour une permutation de chiffrement des blocs , le message chiffré est donc
la séquence des blocs (0), (1), . . .
Les tests portent sur le message chiffré vu comme une séquence de bits, un bit
étant un chiffre
en base 2, soit 0 ou 1. En fonction d'une longueur paramétrable n,
nécessairement multiple
de 64, la séquence étudiée est la séquence
·{z
· · 1110} · · · 1101
·{z
· · 0010}
Sn = 1010
·{z
· · 1101} 1001
|
|
|
(0) (64 bits)
(1) (64 bits)
n
-1) (64 bits)
( 64
où par convention, l'écriture binaire (complète) d'un entier x de [[0, 264 [[,
x =
séquence b63 b62 · · · b1 b0 (le bit « le plus significatif » apparaît en
premier).
P63
i
i=0 bi 2 ,
est la
Dans tout ce qui suit, on considère que la permutation étudiée est fixée, et
calculée par une
fonction Sigma(x), qui prend en entrée un entier x de [[0, 264 [[ et renvoie un
entier de [[0, 264 [[.
Question 10 Écrire la fonction Sequence(n) qui construit la séquence Sn
ci-dessus, sous la forme
d'un tableau de taille n ou d'une liste (on rappelle que n est un multiple de
64). L'ordre des
éléments du tableau ou de la liste sera évidemment l'ordre des bits de Sn
défini précédemment.
Un premier critère consiste à tester dans quelle mesure les bits 0 et 1
apparaissent avec une
fréquence suffisamment proche. Sur un total de n bits (n 1), on calcule pour
cela la valeur
V1 = n1 (n0 - n1 )2 , où n0 et n1 représentent respectivement le nombre de bits
0 et 1 dans la
séquence de n bits considérée. En fonction de cette valeur V1 , des tables
permettent de dire si
un biais statistique est visible.
Question 11 Écrire la fonction CalculerV1(n) qui détermine la valeur V1
correspondant à la
séquence Sn . Attention, on observera que V1 n'est pas un entier, il sera
représenté en machine
par un nombre flottant.
Un second critère généralise le précédent en considérant les séquences de deux
bits. Pour
n bits (n 2), on calcule la valeur V2 donnée par :
2 2
4
n200 + n201 + n210 + n211 -
n0 + n21 + 1,
V2 =
n-1
n
où n00 , n01 , n10 , n11 désignent respectivement le nombre d'occurrences des
séquences 00, 01, 10, 11.
On notera qu'on autorise les séquences de deux bits à se recouper. Ainsi la
séquence de cinq bits
01100 contient exactement une fois chacune des quatre séquences de deux bits
possibles.
Question 12 Écrire la fonction CalculerV2(n) qui détermine la valeur V2
correspondant à Sn .
4