
CCINP Informatique PSI 2016
| Thème de l'épreuve | La mission Cassini-Huygens |
| Principaux outils utilisés | stockage de données, boucles, recherche de maximum, méthode d'Euler |
| Mots clefs | Cassini-Huygens, compression de données, modélisation d'orbite |
Corrigé
: 👈 gratuite pour tous les corrigés si tu crées un compte👈 l'accès aux indications de tous les corrigés ne coûte que 5 € ⬅ clique ici
👈 gratuite pour tous les corrigés si tu crées un compte
- - - - - - - - - - - - - - - - - -
Énoncé complet
(télécharger le PDF)










Rapport du jury
(télécharger le PDF)


Énoncé obtenu par reconnaissance optique des caractères
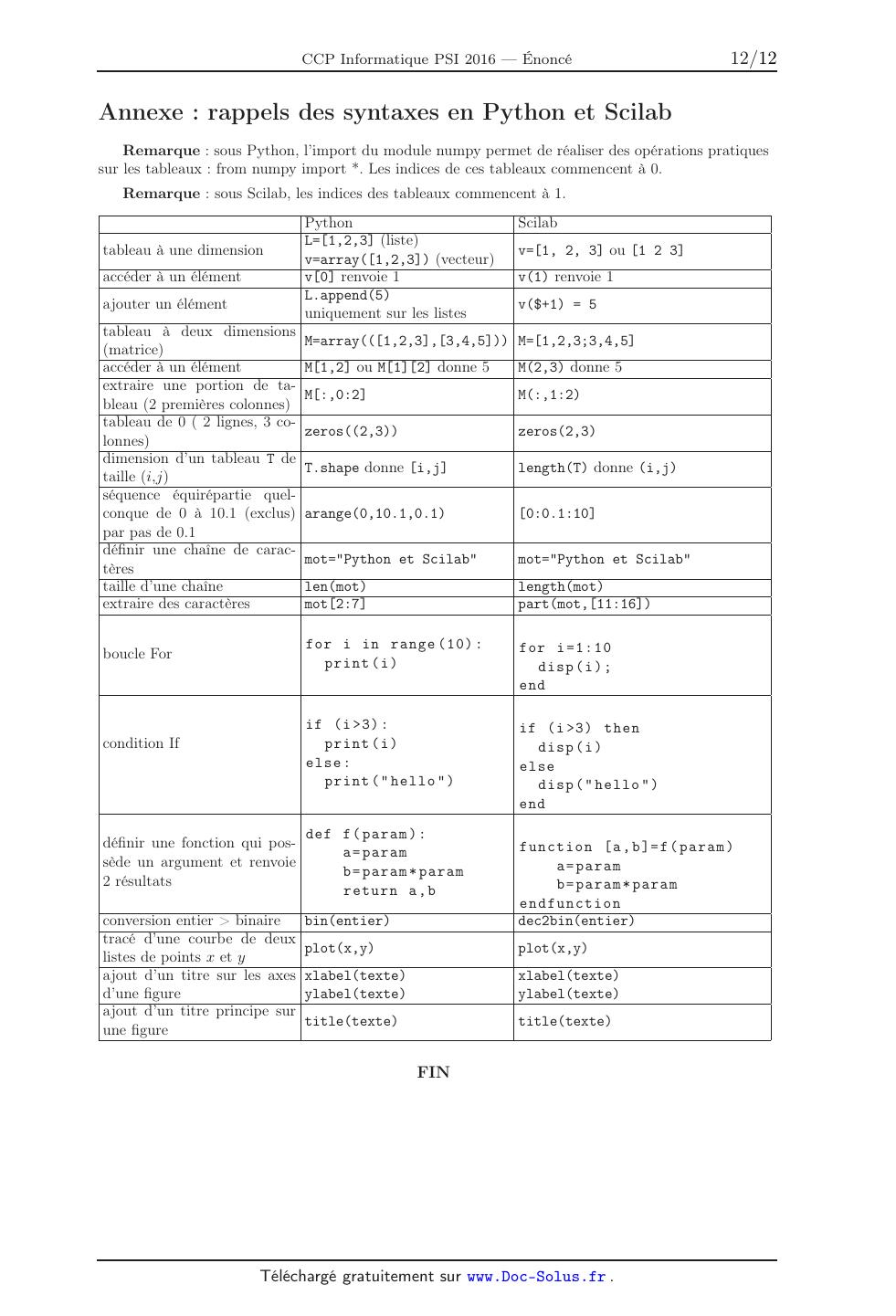
SESSION 2016 PSIIN07 ! ! ! EPREUVE SPECIFIQUE - FILIERE PSI! !!!!!!!!!!!!!!!!!!!!" ! INFORMATIQUE Vendredi 6 mai : 8 h - 11 h! !!!!!!!!!!!!!!!!!!!!" N.B. : le candidat attachera la plus grande importance à la clarté, à la précision et à la concision de la rédaction. Si un candidat est amené à repérer ce qui peut lui sembler être une erreur d'énoncé, il le signalera sur sa copie et devra poursuivre sa composition en expliquant les raisons des initiatives qu'il a été amené à prendre.! ! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!" ! ! ! Les calculatrices sont interdites ! ! ! Le sujet comporte 12 pages dont : ! 11 pages de texte de présentation et énoncé du sujet ; ! 1 page d'annexe. ! Toute documentation autre que celle fournie est interdite. ! ! ! REMARQUES PRELIMINAIRES ! ! ! L'épreuve peut être traitée en langage Python ou langage Scilab. Il est demandé au candidat ! de bien préciser sur sa copie le choix du langage et de rédiger l'ensemble de ses réponses dans ! ce langage. Les syntaxes Python et Scilab sont rappelées en annexe, page 12. ! ! Les différents algorithmes doivent être rendus dans leur forme définitive sur la copie en respec! tant les éléments de syntaxe du langage choisi (les brouillons ne sont pas acceptés). ! ! Il est demandé au candidat de bien vouloir rédiger ses réponses en précisant bien le numéro ! de la question traitée et, si possible, dans l'ordre des questions. La réponse ne doit ! pas se cantonner à la rédaction de l'algorithme sans explication, les programmes doivent être ! expliqués et commentés. ! ! ! 1/12 ! La mission Cassini-Huygens I Introduction La mission spatiale Cassini-Huygens a pour objectif l'exploration de Saturne et de ses nombreux satellites naturels (62 « lunes » identifiées en 2009). Cassini orbite depuis 2004 autour de Saturne et collecte grâce à ses différents instruments d'observation, de précieuses informations sur la planète géante, ses anneaux caractéristiques et ses différents satellites. Le sujet proposé aborde des problématiques associées à différentes phases de la mission : l'acquisition d'images par l'imageur spectral VIMS (Visible and Infrared Mapping Spectrometer) dans le domaine du visible et de l'infrarouge embarqué à bord de la sonde Cassini et la compression des données avant transmission vers la Terre pour leur exploitation, la mise en orbite autour de Saturne de la sonde, en utilisant le phénomène d'assistance gravitationnelle de Vénus, de la Terre, puis de Jupiter. II II.1 Figure 1 La sonde Cassini-Huygens Acquisition d'images par l'imageur VIMS et compression des données Présentation La sonde Cassini embarque à son bord un ensemble de 12 instruments scientifiques destinés à l'étude de Saturne et son système, dont 4 instruments d'observation à distance permettant de couvrir une bande spectrale d'observation très large (figures 2 et 3). Figure 2 Instruments d'observation à distance Figure 3 Domaine de travail des différents instruments d'observation à distance L'un des principaux objectifs scientifiques associés à l'instrument VIMS est de cartographier la distribution spatiale des caractéristiques minéralogiques et chimiques de différentes cibles : anneaux de Saturne, surface de ses satellites, atmosphère de Saturne et Titan, etc. Pour cela, l'instrument VIMS mesure les radiations émises et réfléchies par les corps observés, sur une gamme de 0,35 à 5,1 µm (domaines visible et infrarouge) avec au total 352 longueurs d'onde différentes. 2/12 Les données acquises par l'instrument sont organisées sous la forme d'un cube (figure 4) constitué d'un ensemble de 352 « tranches » (associées aux différentes longueurs d'onde ) comportant 64 pixels dans les deux directions spatiales x et y. Il est ensuite possible d'en extraire une image à une longueur d'onde donnée (k ) ou un spectre associé à un pixel de coordonnées spatiales (xi ,yj ). y : 64 pixels x : 64 pixels : 352 longueurs d'onde Image à une longueur d'onde donnée (k ) Spectre associé à un pixel (xi , yi ) Figure 4 Structure d'un cube de données hyperspectrales Les contraintes technologiques liées au transfert de l'ensemble des données recueillies par la sonde vers la Terre imposent une réduction de leur volume. Pour l'imageur VIMS, cela consiste en une compression des données prise en charge par une unité de traitement numérique embarquée à bord de la sonde. Cette compression doit toutefois s'effectuer sans perte d'information. Après compression, la taille maximale attendue pour un cube de données est de 1 Mo (mégaoctet). Objectif Cette partie s'intéresse à l'implémentation d'algorithmes spécifiques visant à améliorer les performances de la compression en vue d'une mise à jour des programmes de l'unité de traitement embarquée. A chaque pixel pijk du cube de données hyperspectrales (de coordonnées xi , yj et appartenant à une image de longueur d'onde k ) est associé un nombre moyen de photons reçus par les capteurs de l'instrument VIMS. Cette dernière information est codée sur 12 bits. Q1. Déterminer en octets la taille d'un cube de données hyperspectrales avant compression. Si T et Tc représentent respectivement la taille des données avant compression et après c compression, le taux de compression est défini comme : = T -T . T Q2. Déterminer alors le taux de compression à appliquer aux données afin de respecter le cahier des charges. II.2 Principe de la compression des données La compression des données est réalisée à l'issue de l'acquisition d'une ligne (soit 64 pixels pour la dimension spatiale et 352 longueurs d'onde pour la dimension spectrale) par l'imageur 3/12 VIMS. Les données sont traitées par blocs de 64 pixels × 32 longueurs d'onde. L'algorithme mis en oeuvre pour la compression est un algorithme dit entropique, qui réalise un codage des données exploitant la redondance de l'information. L'exemple proposé ci-après permet d'en illustrer le principe, avec le codage d'une suite de 10 entiers naturels. Soit la série Sn de 10 entiers naturels sk [0,8] : 4 - 5 - 7 - 0 - 7 - 8 - 4 - 1 - 7 - 4. Un codage en binaire naturel des entiers 0 à 8 nécessitant au minimum 4 bits, le choix d'un tel codage pour la série Sn conduirait à un code d'une longueur totale de 40 bits. La longueur du code associé à la série Sn peut être réduite en adoptant un codage exploitant les propriétés suivantes de la série : seules 6 valeurs vi sont utilisées parmi les 9 possibles ; certaines valeurs vi possèdent des probabilités pi d'apparition plus importantes que d'autres. Une solution consiste par exemple à adopter un codage à longueur variable, où les codes les plus courts sont associés aux valeurs qui possèdent la probabilité d'apparition la plus importante. Un tel codage est proposé dans le tableau 1 pour les entiers de la série Sn . La série Sn est alors codée de la manière suivante : 4 5 7 0 7 8 4 1 7 4 0 0 1 1 0 1 0 0 1 0 1 0 1 1 1 0 0 0 1 1 1 0 0 0 La longueur du code associé à la série est à présent de 24 bits (soit une longueur moyenne de 2,4 bits par caractère). Le décodage est unique, mais il nécessite la connaissance de la table de codage établissant la correspondance entre un code et la valeur associée. C'est cette stratégie qui est adoptée pour les opérations de compression. Pour la série Sn considérée, avec des valeurs initialement codées sur 4 bits en binaire naturel, le codage à longueur variable présenté permet d'obtenir un taux de compression = 40 %. II.3 valeur vi probabilité pi code 4 0,3 0 0 7 0,3 1 0 0 0,1 0 1 0 1 0,1 0 1 1 5 0,1 1 1 0 8 0,1 1 1 1 Tableau 1 Table de codage Limite du taux de compression Les algorithmes de compression entropiques étant basés sur l'exploitation de la redondance dans les données à coder, leur efficacité est directement liée à la « quantité d'information » qu'elles contiennent : plus il y a répétitions de certaines valeurs dans les données à coder (l'entropie des données est alors faible), plus le taux de compression atteint est élevé. Une valeur limite du taux de compression que l'on peut espérer atteindre peut être approchée par le calcul de l'entropie de Shannon H, grandeur fournissant une mesure de la « quantité d'information » contenue dans les données, en bits par caractère. Pour une série de données Sn (considérée comme une variable aléatoire) l'entropie H est définie de la manière suivante : H(Sn ) = - i=N v pi log2 pi , avec (1) i=1 · Nv : nombre de valeurs vi différentes contenues dans la série ; · pi : probabilité d'apparition de la valeur vi (pi = nni avec ni nombre d'occurrences de la valeur vi et n nombre de termes de la série Sn ) ; où ln est la fonction · log2 : fonction logarithme binaire (base 2). Pour x R, log2 (x) = ln(x) ln(2) logarithme népérien. On suppose que la fonction log2(x) est définie dans le langage de programmation choisi. 4/12 Q3. Calculer l'entropie associeé à l'exemple précédent. En déduire le taux de compression limite de cet exemple et le comparer à la longueur moyenne de 2,4 bits par caractère. Dans le cadre d'une étude visant à améliorer les performances de la compression des données, les ingénieurs souhaitent caractériser l'entropie des images acquises par l'instrument VIMS. La fonction entropie(S) dont le code est partiellement présenté ci-après reçoit en argument d'entrée une série d'entiers naturels S sous forme de tableau à une dimension (liste en Python) et renvoie la valeur H de l'entropie de Shannon associée. Code Python de la fonction entropie(S) : Code Scilab de la fonction entropie(S) : def entropie (S) : # 1 .COMMENTAIRE1 à compl é t e r à l a q u e s t i o n Q4 v a l e u r s= l i s t ( s e t ( S ) ) # 2 .Dé t e r m i n a t i o n du nombre d ' o c c u r e n c e s ( nombre d ' a p p a r i t i o n s ) occ_i de chaque v a l e u r v_i e t c a l c u l de l a p r o b a b i l i t é proba [ i ] a s s o c i é e . # QUESTION Q5 : zone à compl é t e r # 3 . C a l c u l de l ' e n t r o p i e de Shannon H # QUESTION Q6 : zone à compl é t e r return H // DEFINITION DE LA FONCTION ENTROPIE f u n c t i o n H=e n t r o p i e ( S ) // 1 . COMMENTAIRE1 à compl é t e r à l a q u e s t i o n Q4 v a l e u r s=u n i q u e ( S ) // 2 .Dé t e r m i n a t i o n du nombre d ' o c c u r e n c e s ( nombre d ' a p p a r i t i o n s ) occ_i de chaque v a l e u r v_i e t c a l c u l de l a p r o b a b i l i t é proba [ i ] a s s o c i é e . // QUESTION Q5 : zone à compl é t e r // 3 . C a l c u l de l ' e n t r o p i e de Shannon H // QUESTION Q6 : zone à compl é t e r endfunction La fonction réalise différentes étapes. La première étape utilise la fonction set en Python ou unique en Scilab. Un exemple extrait de la documentation de la fonction set est donnée ci-dessous. En Python, il faut transformer le résultat en list pour itérer sur le résultat de set (le principe est similaire en Scilab avec la fonction unique). >>> b a s k e t = [ ' a p p l e ' , ' orange ' , ' a p p l e ' , ' pear ' , ' orange ' , ' banana ' ] >>> f r u i t = s e t ( b a s k e t ) # c r e a t e a s e t without d u p l i c a t e s >>> f r u i t s e t ( [ ' orange ' , ' pear ' , ' a p p l e ' , ' banana ' ] ) >>> ' orange ' i n f r u i t # f a s t membership t e s t i n g True >>> ' c r a b g r a s s ' i n f r u i t False Q4. Compléter le commentaire 1 de la fonction entropie(S) correspondant à la ligne de programme définissant la variable valeurs. Q5. Compléter la 2e étape de la fonction entropie(S) à partir du commentaire afin de calculer les probabilités pi . Q6. Compléter la 3e étape de la fonction entropie(S) afin de calculer l'entropie de Shannon H définie par l'équation (1). Suite à une acquisition d'image par l'instrument VIMS, l'utilisateur dispose de données brutes dont il souhaite évaluer l'entropie. Un bloc élémentaire de données se présente sous la forme d'un tableau à une dimension bloc_image constitué de valeurs entières (allant de 0 à 4 095 = 212 - 1). Q7. Ecrire la suite d'instructions permettant de calculer et d'afficher la valeur du taux de compression limite associé aux données contenues dans le tableau bloc_image. II.4 Prétraitement des données avant compression Les données brutes sont traitées par blocs correspondants à une acquisition de 64 pixels (dimension spatiale y) par 32 longueurs d'onde (dimension spectrale ). Ces données sont organisées sous forme d'une matrice donnees_brutes composée de 32 lignes et 64 colonnes. 5/12 Une stratégie efficace permettant d'améliorer la compression consiste à réaliser un prétraitement des données visant à réduire leur entropie. Il a été constaté pour les images acquises par l'instrument VIMS que les importantes variations de luminance (intensité lumineuse par unité de surface) constituent la contribution dominante dans l'entropie des données. Ainsi, le prétraitement consiste à estimer ces variations, puis à les soustraire aux données brutes à compresser afin de constituer un nouvel ensemble de données, d'entropie inférieure. La procédure de prétraitement consiste d'abord à construire une matrice modèle matrice_modele permettant d'estimer les variations de luminance associées au bloc de données brutes, suivant les étapes décrites ci-après : 1. construction d'une ligne luminance_moy représentative de la luminance moyenne, en effectuant la moyenne de 4 lignes de la matrice donnees_brutes régulièrement espacées et associées à différentes longueurs d'ondes i , i = 1, 11, 21, 31 ; 2. identification du pixel de luminance maximale (de valeur luminance_max) dans la ligne moyenne luminance_moy construite à l'étape précédente ; 3. extraction d'un vecteur colonne spectre_max contenant le spectre (32 composantes) associé au pixel de luminance maximale ; 4. normalisation du vecteur spectre_max en divisant (division réelle) chacune de ses composantes par la valeur luminance_max relevée à l'étape 2. Le résultat est une liste contenant des réels ; 5. construction de la matrice modèle matrice_modele de dimension (32 lignes, 64 colonnes) en effectuant le produit du vecteur colonne spectre_max par la ligne de luminance moyenne luminance_moy. Q8. A partir de la description des étapes 1 et 2, écrire une fonction pretraitement12(donnees_ brutes) recevant en argument d'entrée la matrice donnees_brutes et renvoyant le vecteur ligne luminance_moy, la valeur de luminance maximale luminance_max relevée pour cette ligne moyenne, ainsi que l'indice j (variable j_max) associé (sans utiliser la fonction max interne au langage). Q9. A partir de la description des étapes 3 et 4, écrire une fonction pretraitement34(donnees_ brutes, luminance_max,j_max) recevant en argument d'entrée la matrice donnees_brutes, la valeur de luminance maximale luminance_max ainsi que l'indice j_max et renvoyant le vecteur colonne spectre_max normalisé. Q10. A partir de la description de l'étape 5, écrire une fonction pretraitement5(luminance_ moy, spectre_max) recevant en argument d'entrée le vecteur ligne luminance_moy, le vecteur colonne spectre_max et renvoyant la matrice modèle matrice_modele. La matrice modèle matrice_modele obtenue constitue une estimation des variations de luminance associées au bloc de données brutes. Elle est alors soustraite à la matrice donnees_ brutes pour construire la matrice de données prétraitées matrice_pretraitee. Q11. Evaluer la complexité calculatoire (additions, soustractions, ...) associée à chacune des fonctions de prétraitement, en fonction des dimensions de la matrice modèle (n lignes, m colonnes). En déduire la complexité calculatoire de la phase de prétraitement. II.5 Compression des données Les données de la matrice matrice_pretraitee, d'entropie réduite, sont ensuite envoyées vers le compresseur qui prend en charge leur compression. Il en est de même pour les vecteurs 6/12 luminance_moy et spectre_max qui sont nécessaires à la reconstruction des données après réception. L'architecture fonctionnelle du compresseur qui prend en charge ces opérations est décrite sur la figure 5. Données d'entrée x Prédicteur Mappeur Données compressées y Encodeur entropique Compresseur Figure 5 Architecture fonctionnelle du compresseur Le compresseur est composé : d'un prédicteur, qui effectue une prédiction xk pour chaque échantillon xk des données d'entrée x. La prédiction xk est réalisée simplement ici, en prenant la valeur xk-1 de l'échantillon précédent. Le prédicteur retourne l'erreur k , différence entre la valeur de l'échantillon xk et la prédiction xk ; d'un mappeur, qui réalise un mappage (correspondance) entre l'erreur de prédiction k et un entier non signé k représenté avec un nombre de bits équivalent à celui de l'échantillon xk ; d'un encodeur entropique, qui réalise un codage sans perte des valeurs k en exploitant la redondance des données tel que présenté en partie II.2, page 3. II.5.1 Prédiction-mappage k xk xk k k k Le sous-ensemble prédicteur-mappeur a pour fonc1 2 025 -- -- -- -- tion d'associer aux échantillons d'entrée xk une série 2 2 027 2 025 2 2 025 4 d'entiers k . Cette association est réalisée de telle sorte 3 2 032 2 027 5 2 027 10 que les valeurs k les plus faibles (donc celles qui pourront être codées avec le moins de bits) sont celles qui 4 2 041 2 032 9 2 032 18 ont la probabilité d'apparition la plus élevée. 5 2 050 2 041 9 2 041 18 Pour l'application proposée ici, le compresseur reçoit 6 2 053 2 050 3 2 045 6 en entrée les données x constituées d'un paquet de 32 7 2 052 2 053 -1 2 042 1 échantillons xk . Les échantillons xk considérés étant des entiers naturels représentés sur 12 bits, les valeurs asso8 2 050 2 052 -2 2 043 3 ciées appartiennent à l'intervalle I = [0 , 4 095 = 212 -1]. .. .. .. .. .. .. . . . . . . Le tableau 2 illustre les opérations réalisées par le prédicteur et le mappeur permettant d'obtenir la série Tableau 2 Illustration de la de valeur k : prédiction et du mappage de l'er le premier échantillon x1 = 2 025 est un échantillon reur associée de référence sur lequel se base la prédiction au rang suivant x2 ; à partir du deuxième échantillon, l'erreur de prédiction k = xk - xk est calculée ; un entier non signé k est associé à l'erreur de prédiction k par la fonction de mappage définie comme : si 0 k k 2k (2) k = 2|k | - 1 si - k k < 0 + | | sinon k k avec k = min(xk - xmin , xmax - xk ), soit ici : k = min(xk , 4 095 - xk ). 7/12 Q12. Ecrire une fonction prediction(x) recevant en argument d'entrée le tableau à une dimension x et renvoyant le tableau erreur contenant les valeurs k . Q13. A partir de la définition de la fonction de mappage, équation (2), écrire une fonction mappage(erreur,x) recevant en arguments d'entrée les tableaux à une dimension erreur et x et renvoyant le tableau delta contenant les valeurs k . II.5.2 Codage entropique - Algorithme de Rice L'ensemble de valeurs k est ensuite codé en utilisant un codage entropique spécifique : le codage de Rice. Celui-ci est particulièrement adapté à la compression de données dans lesquelles les valeurs les plus faibles sont celles qui ont la probabilité d'apparition la plus élevée, mais également lorsque la vitesse d'exécution de l'algorithme est un paramètre important. Le principe du codage d'un entier N avec l'algorithme de Rice de paramètre p est le suivant : l'entier N à coder est divisé par 2p (division entière) ; le quotient q de la division entière est codé avec un codage unaire (q occurences de 1 suivies d'un 0, voir tableau 3), ce qui constitue la première partie du code de Rice ; le reste r de la division entière est codé en binaire sur p bits, ce qui constitue la seconde partie du code de Rice. Le tableau 4 illustre le codage des entiers 0 à 7 avec un codage de Rice de paramètre p = 2. Une procédure d'analyse de l'ensemble de valeurs k à coder permet de déterminer la valeur optimale popt du paramètre p. Le codage de chaque valeur k est ensuite réalisé par une fonction codage(delta_k,p_opt) recevant en argument d'entrée la valeur k et l'entier popt et renvoyant le code de Rice associé. Q14. Déterminer le code de Rice associé à la suite de valeurs k données dans le tableau 2, page 7 pour p = 3. Q15. Définir la suite d'instructions de la fonction codage(delta_k,p_opt) permettant d'obtenir un tableau à une ligne code1 associé à la première partie du code de Rice (codage unaire du quotient). Q16. Définir la suite d'instructions de la fonction codage(delta_k,p_opt) permettant d'obtenir un tableau à une ligne code2 associé à la seconde partie du code de Rice (codage binaire du reste) et réalisant ensuite l'assemblage des deux parties dans le tableau code. Les instructions bin de Python ou dec2bin de Scilab (voir annexe, page 12) pourront être utilisées (on supposera que ces fonctions retournent une chaîne de caractères associée au code binaire). Décimal Code unaire 0 0 1 10 2 110 3 1110 4 11110 5 111110 6 1111110 7 11111110 Décimal Rice p = 2 0 0 00 1 0 01 2 0 10 3 0 11 4 10 00 5 10 01 6 10 10 7 10 11 Tableau 3 Codage unaire des entiers 0 à 7 Tableau 4 Codage de Rice de paramètre p = 2 des entiers 0 à 7 8/12 III III.1 Mise en orbite de la sonde autour de Saturne Présentation La sonde Cassini-Huygens a été lancée du site de Cap Canaveral (Floride - USA) le 15 Octobre 1997. Une fusée Titan IV-B/Centaur a été nécessaire pour assurer le lancement de cette sonde de 5,6 tonnes. Aucun lanceur n'étant alors capable de donner à une sonde spatiale de cette masse l'énergie suffisante pour rejoindre Saturne par une trajectoire directe, l'énergie manquante est obtenue en utilisant le phénomène d'assistance gravitationnelle de Vénus, de la Terre et enfin de Jupiter. L'assistance gravitationnelle consiste à utiliser le champ de gravitation d'une planète afin de fournir une accélération supplémentaire à la sonde. Le trajet de la sonde vers Saturne s'est donc effectué en plusieurs étapes comme indiqué sur la figure 6. Figure 6 Trajet de la sonde depuis la Terre vers Saturne Objectif L'objectif de cette partie est de simuler le mouvement de la sonde lors de la phase d'assistance gravitationnelle de Vénus afin de déterminer sa trajectoire ainsi que le gain de vitesse obtenu. III.2 Modélisation du mouvement de la sonde lors de la phase d'assistance gravitationnelle Paramétrage Le mouvement de la sonde est étudié dans le référentiel héliocentrique auquel est associé le repère (O, x, y ). La sonde est repérée par la position de son centre d'inertie G auquel est associé le vecteur - r(t) = OG et l'angle (t). La planète Vénus est repérée par la position de son centre d'inertie Gv auquel est associé -- le vecteur rv (t) = OGv et l'angle v (t). 9/12 Hypothèses Seuls le Soleil et Vénus ont une influence gravitationnelle significative sur la trajectoire de la sonde. Le propulseur de la sonde n'étant pas utilisé lors du survol de Vénus, sa poussée n'est pas prise en compte. Les trajectoires de la sonde et de Vénus sont considérées comme coplanaires (plan O, x, y ). Aussi, les vecteurs position s'expriment en coordonnées cartésiennes : r(t) = x(t) x + y(t) y rv (t) = xv (t) x + yv (t) y L'orbite de Vénus autour du Soleil, considérée comme quasiment circulaire, est décrite par les équations : xv (t) = rv cos(t + ) yv (t) = rv sin(t + ) y Orbite de la Terre Position de la Terre au 26 avril 1998 Orbite de Vénus Terre G r(t) Position de Vénus au 26 avril 1998 Gv Vénus v (t) rv (t) (t) x O Soleil Terre Trajectoire de la sonde Position de la Terre au lancement Figure 7 Paramétrage du mouvement avec rv = 1,082 09 × 1011 m, = v (t) = 3,236 39 × 10-7 rad · s-1 et la position angulaire initiale de Vénus. Equations de mouvement Le mouvement de la sonde est défini par l'équation suivante : d2r(t) r(t) r(t) - rv (t) = - Gms - Gmv 2 3 dt ||r(t)|| ||r(t) - rv (t)||3 (3) avec G constante universelle de gravitation, ms masse du Soleil, mv masse de Vénus (GmS = 1,327 24 × 1020 N · m2 · kg-1 et GmV = 3,249 16 × 1014 N · m2 · kg-1 ). On note m la masse de la sonde. Q17. Indiquer comment a été obtenue cette équation en précisant le théorème utilisé et ce que représentent chacun des termes. L'équation précédente peut se mettre sous la forme : d2 x(t) = Sx (x(t),y(t),t) dt2 (4) d2 y(t) = Sy (x(t),y(t),t) dt2 (5) Q18. Donner les expressions des fonctions Sx et Sy . Ecrire une fonction eval_sm(x,y,t), qui prend en argument les coordonnées x et y et l'instant t et qui renvoie les valeurs Sx et Sy associées. 10/12 III.3 III.3.1 Résolution numérique Méthode numérique La résolution numérique des équations différentielles (4) et (5) repose sur leur discrétisation temporelle et conduit à déterminer à différents instants ti une approximation de la solution. On note ui et vi , les approximations des composantes du vecteur vitesse (vx (t),vy (t)) à dx(t) dy(t) l'instant ti avec vx (t) = et vy (t) = . On note t = ti+1 - ti . dt dt Q19. En appliquant la méthode d'Euler explicite, déterminer les deux relations de récurrence reliant ui+1 à ui , Sx et t ainsi que vi+1 à vi , Sy et t. On note xi et yi , les approximations des composantes du vecteur position (x(t),y(t)) à l'instant ti . Q20. En appliquant la méthode d'Euler explicite, déterminer les deux relations de récurrence reliant xi+1 à xi , ui et t ainsi que yi+1 à yi , vi et t. III.3.2 Le programme de résolution On supposera toutes les constantes du problème définies comme variables globales et donc utilisables directement dans votre programme. Les conditions initiales du problème seront supposées être : u0 = vx (t = 0), v0 = vy (t = 0), x0 = x(t = 0), y0 = y(t = 0). Le programme doit permettre de calculer les quatre vecteurs : x(t), y(t), u(t) et v(t), contenant les différentes valeurs pour les différents instant ti , qui seront stockés respectivement dans les variables x, y, u et v. Le programme est constitué de trois étapes : initialisation des variables, résolution et traitement. On définira également le vecteur temps contenant l'ensemble des instants de calcul ti de longueur n et qui sera stocké dans la variable t. Q21. Donner les lignes de programme permettant de définir et d'initialiser les quatre variables x, y, u et v ainsi que le vecteur t contenant l'ensemble des instants de calcul ti de longueur n sachant que la variable deltaT égale à t et la variable n sont déjà déclarées. Q22. Donner les lignes de programme permettant de calculer les vecteurs x, y, u et v en utilisant les relations de récurrence définies précédemment. Q23. Donner un ordre de grandeur de la quantité de mémoire nécessaire pour réaliser cette simulation numérique pour une durée de simulation de 30 jours et pour un pas de temps de 1 seconde sachant que les variables x, y, u et v contiennent des flottants codés sur 8 octets. Conclure sur la faisabilité de la simulation par cette méthode. III.4 Evolution de la vitesse Q24. Afin de quantifier le gain de vitesse obtenu par l'assistance gravitationnelle étudiée, écrire une fonction vitesse_sonde dont vous préciserez les arguments et les valeurs retournées, permettant d'afficher l'évolution de la norme de la vitesse v (t) de la sonde en fonction du temps t. Les vitesses seront exprimées en km · s-1 et les axes seront légendés. On pourra utiliser les informations données en annexe pour l'utilisation des commandes de tracés. 11/12 Annexe : rappels des syntaxes en Python et Scilab Remarque : sous Python, l'import du module numpy permet de réaliser des opérations pratiques sur les tableaux : from numpy import *. Les indices de ces tableaux commencent à 0. Remarque : sous Scilab, les indices des tableaux commencent à 1. accéder à un élément ajouter un élément tableau à deux dimensions (matrice) accéder à un élément extraire une portion de tableau (2 premières colonnes) tableau de 0 ( 2 lignes, 3 colonnes) dimension d'un tableau T de taille (i,j) séquence équirépartie quelconque de 0 à 10.1 (exclus) par pas de 0.1 définir une chaîne de caractères taille d'une chaîne extraire des caractères boucle For condition If définir une fonction qui possède un argument et renvoie 2 résultats conversion entier > binaire tracé d'une courbe de deux listes de points x et y ajout d'un titre sur les axes d'une figure ajout d'un titre principe sur une figure Scilab v=[1, 2, 3] ou [1 2 3] v(1) renvoie 1 v($+1) = 5 M=array(([1,2,3],[3,4,5])) M=[1,2,3;3,4,5] M[1,2] ou M[1][2] donne 5 M(2,3) donne 5 M[:,0:2] M(:,1:2) zeros((2,3)) zeros(2,3) T.shape donne [i,j] length(T) donne (i,j) arange(0,10.1,0.1) [0:0.1:10] mot="Python et Scilab" mot="Python et Scilab" len(mot) mot[2:7] length(mot) part(mot,[11:16]) for i in range (10) : print ( i ) for i =1:10 disp ( i ) ; end if (i >3) : print ( i ) else : print ( " hello " ) if (i >3) then disp ( i ) else disp ( " hello " ) end def f ( param ) : a = param b = param * param return a , b bin(entier) function [a , b ]= f ( param ) a = param b = param * param endfunction dec2bin(entier) plot(x,y) plot(x,y) xlabel(texte) ylabel(texte) xlabel(texte) ylabel(texte) title(texte) title(texte) FIN 12/12 I M P R I M E R I E N A T I O N A L E 16 1226 D'après documents fournis tableau à une dimension Python L=[1,2,3] (liste) v=array([1,2,3]) (vecteur) v[0] renvoie 1 L.append(5) uniquement sur les listes